
Grok Imagine Video 1.5 提示词指南:最佳实践、公式与示例(2026)
日期: 2026年6月4日 (更新)
作者: Jsam(Klingaio 技术专家)
欢迎来到 AI 生成媒体的下一个进化阶段。尽管 2026 年初是由像 Kling AI 3.0 这样的无声物理模型主导,但 xAI 推出的 Grok Imagine Video 1.5 为我们创作视频的方式带来了重大变革。
我们不再仅仅是导演无声的画面;我们正在 指挥一场完整的视听交响乐。
借助 Grok Imagine 1.5 的 原生多模态音频,视频 token 和音频波形在单次推理过程中被联合处理。这意味着拟音、对话、环境噪音以及物理运动在时间线上直接同步。
经过大量多模态测试和社区作品整理,我们开发出了终极的 Grok Imagine 1.5 提示词指南。本教程提供了精确的公式、故障排除流程以及可直接复制粘贴的示例,帮助您掌握这一新世代的视听 AI 视频。您可以直接在我们的 Grok Imagine 1.5 AI 视频生成器 上测试这些提示技巧。

范式转变:专注于运动,而非描述
创作者在从文生视频模型转向 Grok Imagine 1.5(它严格来说是一个 图像转视频 引擎)时,最常见的错误之一就是重新描述起始图像。
Grok Imagine 1.5 的黄金法则: 模型已经看到了你的源图像。不要告诉它画面里有什么,而要告诉它画面中的东西应该如何移动、互动以及发出声音。
由于 Grok Imagine Video 1.5 作为图像转视频(I2V)引擎运行,你视频的质量取决于你的起始图像。我们强烈建议使用像 GPT Image 2 这样的高级图像生成器,在开始动画之前建立一个高度详细、逼真的起始帧。
模型的核心能力:
- 单次通过的同步拟音: 玻璃破碎、雨点敲击或汽车引擎轰鸣,都会精确地随着屏幕上的动作同步发生。
- 环境声学: 模型理解空间声学(例如,铺瓷砖的浴室和开阔森林之间的混响差异)。
- 语音与语调控制: 指导角色讲话风格、低语或戏剧性停顿。
- 15秒连续性: 单次渲染可生成高达 15 秒、24fps 的高保真 720p 视频(不过 5-8 秒区间仍然是视觉稳定性的最佳选择)。
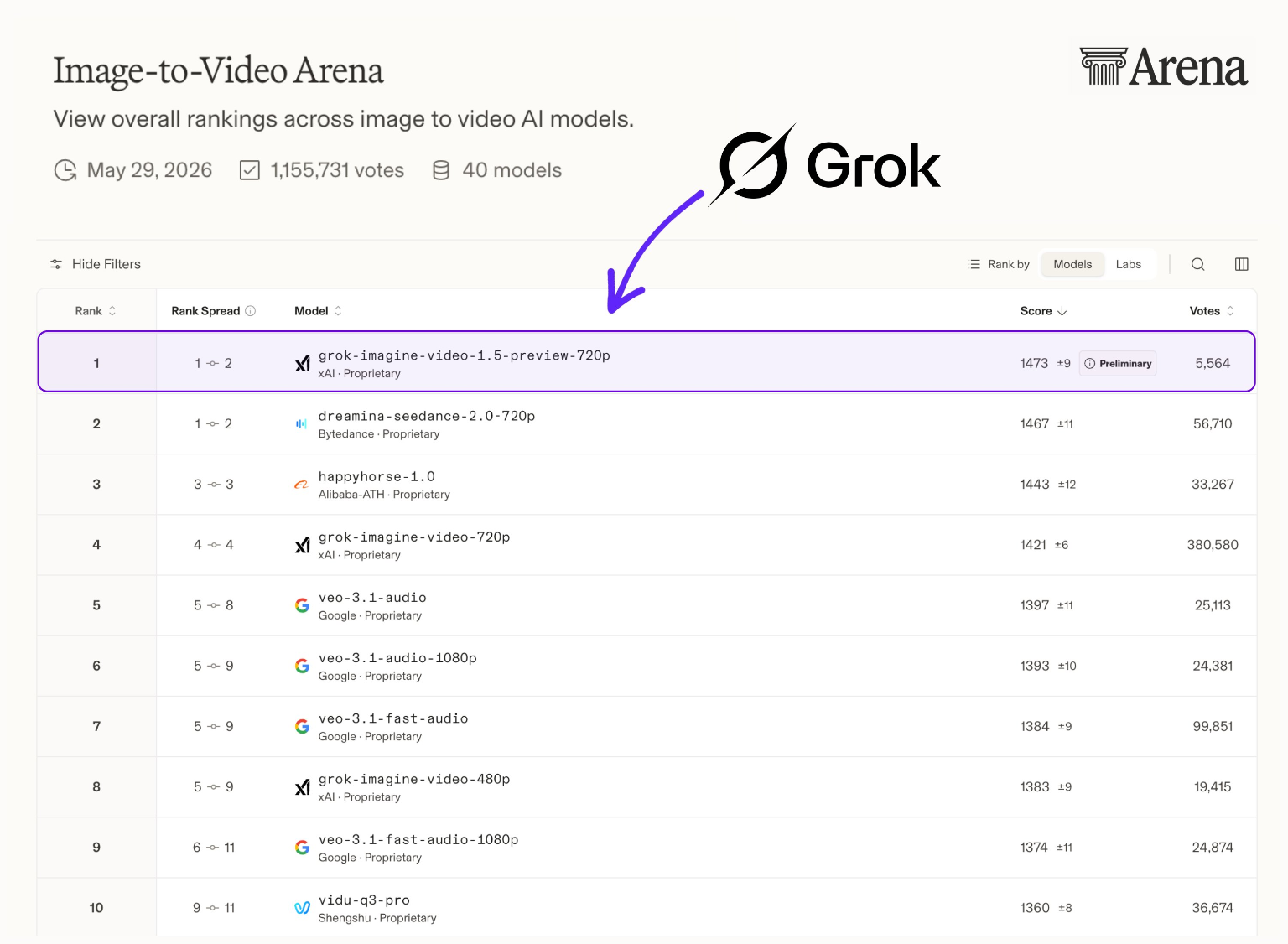
排行榜备注: Grok Imagine Video 1.5 预览版目前在 Arena AI 图像转视频排行榜 上排名第一,其原生音频能力获得了极大的用户偏好。
主公式:构建 Grok Imagine Video 1.5 提示词的结构
为了充分利用 Grok Imagine Video 1.5,我们将视觉运动与音频提示分离开来,使用官方的 AUDIO: 参数放在提示词末尾。
避免使用无结构的标签堆叠(例如“史诗、8K、电影感”),这类提示很大程度上会被模型忽略。相反,应使用这种分层逻辑来构建你的输入:
[主体运动 + 强度修饰词] + [镜头运动与景别] + [灯光与氛围变化] + AUDIO: [环境噪音、动作拟音、对话指令]
🏆 精选片段:弱提示 vs. 强提示
由于模型同时生成音频和视频,弱提示会导致音效泛泛且不同步。以下是优化提示的方法:
| 元素 | 弱提示(不要用) | 强 Grok Imagine 1.5 提示(用这个!) |
|---|---|---|
| 视觉动作 | 一个铁匠在工坊里加工热金属。 | 铁匠用强力将沉重的铁锤砸向炽热的橙色金属,导致明亮火花向外飞溅。 |
| 镜头 | 放大 | 缓慢、紧张的微距推镜,聚焦于铁锤的撞击点。 |
| 音频 | 声音:铁匠噪声 | AUDIO: 一种响亮、有节奏的金属敲击声,滋滋作响的铁器声,背景中锻造炉火的深沉咆哮。 |
| 声学 | 真实音频 | 锤击声在砖砌工坊内回响,带有深邃的混响。 |
5 个进阶 Grok Imagine Video 1.5 提示词示例(可直接使用)
以下是五个经过优化的提示词模板,旨在利用 Grok Imagine Video 1.5 的原生视听逻辑。使用 GPT Image 2 生成你的起始帧,然后将这些提示词输入我们的 Grok Imagine 1.5 网页应用。
1. 电影级拟音与大气物理
目标:实现物理冲击的帧级精确视听同步。
慢动作微距跟踪镜头,拍摄从生锈管道滴落到水坑中的水滴。每滴水滴撞击水面,产生同心波纹。
AUDIO: 深邃空洞的滴水声,轻柔的水花飞溅声,伴有高音滴落,远处传来低沉的雷雨轰鸣声在回荡。
- 为何有效: 描述物理冲击(“水滴撞击水面”)结合高度具体的拟声词(“空洞的滴水”、“轻柔地飞溅”),能够指导模型将音频波形绑定到对应的视频帧上。
输入图像(起始帧):

生成视频(含原生音频):
2. 角色对话与配音
目标:利用原生语音合成,实现精准的嘴部动作匹配。
侦探缓慢地将头转向右侧,直视镜头说话,轻微的手持摄像头抖动增加了紧张感。
AUDIO: 轻柔沙哑的低语声:‘我们成功了。但时钟在滴答作响。’背景中传来微弱的纸张翻动声,以及低沉时钟的滴答声。
- 为何有效: 在
AUDIO:区块内标准化对话输入,有助于 Grok Imagine 1.5 隔离语音轨道,并自然地同步嘴唇动作,而不干扰视觉动画。
3. 质感商业产品特写
目标:展示稳定的文本和优雅的环境音频。
浓缩咖啡杯在底座上平稳旋转,镜头在视线高度环绕,温暖的金色时光扫过大理石台面的表面。
AUDIO: 蒸汽高压嘶嘶声,热浓缩咖啡稳定滴入杯中,瓷器轻微碰撞声,轻柔的背景爵士乐。
- 为何有效: 它将高端视觉产品渲染与环境音结合,创造出完整的感官广告。对于需要严格保留标志和文本的商务应用,你可以使用字节跳动的 Seedance 2.0 进行交叉测试。
输入图像(起始帧):

生成视频(含原生音频):
4. 悬疑科幻动作(动态音频)
目标:生成与高科技镜头运动同步的重型机械音效。
FPV 无人机镜头,穿梭在星舰狭窄黑暗的金属走廊中。红色紧急警告灯有节奏地闪烁。一扇沉重的钢制防爆门缓慢滑动关闭。
AUDIO: 沉重钢门滑动时发出的巨大、低沉的机械摩擦声,警报器鸣响,星舰反应堆核心的低频嗡嗡声。
- 为何有效: 高速镜头运动搭配沉重、刺耳的机械音效,测试了模型将响亮音效与快速移动的环境物体同步的能力。
5. 多镜头叙事与连续性(15秒最佳实践)
目标:在特定秒数强制进行硬切,同时过渡音频时间线。
(0-3秒) 广角定场镜头,展现冬日柔和暴风雪中一座静谧小屋坐落在雪松林中。
(3-7秒) 切换到内部特写镜头,拍摄粗犷的石砌壁炉,柴火噼啪作响;接着一只手缓缓将热气腾腾的茶倒入木制杯中。
(7-12秒) 切换到过肩镜头,一个人透过舒适的小屋窗户看着外面的飘雪,温柔微笑。光泽、温暖、电影感。
AUDIO: (0-3秒) 外面低沉的风雪呼啸声,(3-7秒) 壁炉清脆的噼啪声和柔和的液体倾倒嘶嘶声,(7-12秒) 轻柔的原声吉他旋律和一声满足的轻叹。
- 为何有效: 指定精确的时间标记,如
(0-3秒)和(3-7秒),告诉转换引擎何时触发场景切换以及何时转变声音声学。这防止了经典的 AI 错误,即不同镜头混合或“变形”在一起。
输入图像(起始帧):

生成视频(含原生音频):
故障排除:修复常见的 Grok Imagine 1.5 伪影
即使是原生视听生成,多模态管线也可能会遇到问题。以下是排查最常见错误的方法:
1. 如何修复缓慢或迟钝的物理运动
- 问题: Grok Imagine 1.5 默认生成高度电影化、慢节奏的运动。快速的物理动作(如武术或体育运动)可能会显得迟钝。
- 解决方法: 模型对强度修饰词反应强烈。使用具体的、高速的动词和副词来强制快速动作。不要写“汽车经过”,而是写“汽车高速飞驰而过”。不要写“翅膀扇动”,而是写“翅膀大幅度扇动”。对于高度风格化的卡通或超快动画工作流,你也可以探索像 Nano Banana Pro 这样的轻量级专用管线。
2. 不要使用负面提示词
- 问题: 你输入负面提示词,比如“变形、多余手指、文字变化”,来修复视觉错误,但输出并没有改变。
- 解决方法: Grok Imagine 1.5 会忽略负面提示词。 与其告诉模型 不要 做什么,不如专注于描述你想要看到的正面状态。
3. 如何修复文字和 Logo 变形
- 问题: 由于 Grok Imagine 1.5 针对流畅的电影化场景进行了优化,瓶子或包装上的小文字在镜头旋转时可能会漂移。
- 解决方法: 如果你正在运行电商或产品推广活动,需要严格的品牌一致性,尝试将你的结果与 Seedance 2.0 进行比较(它在细节保留方面表现出色),或者使用 Kling 3.0 来获得复杂的视觉一致性。
结论:停止渲染无声视频
无声 AI 视频的时代正接近尾声。通过掌握 Grok Imagine Video 1.5 的双提示结构,你可以生成完整的、感官丰富的 15 秒序列,大大减少后期制作的工作量。
掌握 Grok Imagine Video 1.5 的关键在于将声音视为视觉物理的活跃参与者。立即尝试这些公式,在 GPT Image 2 上生成你的起始帧,然后直接在 Grok Imagine 1.5 生成器 上创建完整的高保真视频。或者,如果你想探索不同的生成选项,可以返回我们的主 Klingaio 主页。
常见问题解答(FAQ)
问:Grok Imagine 1.5 支持文生视频吗?
答:不支持。当前版本严格来说是一个图像转视频(I2V)模型。你必须上传一张起始图像来引导生成。对于原生、高动态的文生视频,你可以使用 Kling 3.0。
问:Grok Imagine Video 1.5 一次能生成多长的视频?
答:该模型原生支持 1 到 15 秒的生成,以每秒 24 帧(fps)渲染。通常认为 5-8 秒是视觉稳定性的最佳区间。
问:我可以禁用 Grok Imagine Video 1.5 的音频生成器吗?
答:可以。如果你在提示词中不包含 AUDIO: 参数或任何声音描述,模型将输出一个标准的无声 MP4 文件。
问:Grok Imagine 1.5 有免费试用吗?
答:有的。你可以直接在我们的网页应用 /grok-imagine/grok-imagine-15 上测试并使用 Grok Imagine 1.5 生成视频。