Qwen3.5 from Alibaba: Next-Gen Open-Source Multimodal LLM with Native Agent Capabilities
Date: February 16, 2026
Category: Artificial Intelligence, Open Source LLMs, Multimodal AI
Reading Time: 8 Minutes

The open-source AI landscape witnessed a pivotal moment today. On February 16, 2026, the Qwen Team at Alibaba Cloud officially released Qwen3.5, comprising two new models: Qwen3.5-Plus and Qwen3.5-397B-A17B (the first open-weight version in the Qwen 3.5 series).
Qwen3.5-Plus is positioned as the latest large language model in the Qwen3.5 series, while Qwen3.5-397B-A17B is positioned as the flagship large language model in the open-source Qwen 3.5 series. Both models support text and multimodal tasks.
Moving beyond the industry's obsession with raw parameter scaling, Qwen3.5 represents a "humble leap" forward. It prioritizes architectural efficiency, native multimodal understanding, and massive-scale reinforcement learning to deliver a model that is accessible yet performs at the frontier level.
In this technical review, we explore the specifications, architecture, benchmark performance, and deployment strategies for Qwen3.5, helping developers understand why this model is a significant upgrade for AI agents.
Qwen3.5-397B-A17B – Key Highlights

🚀 First open-weight model of the Qwen3.5 series – now released!
🖼️ Native multimodal, built & trained for real-world agents
✨ Hybrid linear attention + sparse MoE + massive RL scaling
⚡ 8.6–19.0× faster decoding than Qwen3-Max
🌍 Supports 201 languages & dialects
📜 Apache 2.0 licensed – fully open
Architecture: Efficiency Through Innovation
The defining characteristic of Qwen3.5 is its ability to do more with less. While the headline parameter count is 397 billion, the model utilizes a sophisticated Sparse Mixture-of-Experts (MoE) architecture that activates only 17 billion parameters per forward pass.
This design allows Qwen3.5 to maintain the vast knowledge base of a 400B+ model while running with the inference latency and cost profile of a much smaller model.
Key Technical Specifications
According to the official technical report, the Qwen3.5-397B-A17B features:
- Total Parameters: 397B (17B Activated)
- Architecture: Hybrid Gated DeltaNet (Linear Attention) + MoE
- Layer Structure: 60 Layers. Layout: 15 blocks of
[3× (Gated DeltaNet → MoE) → 1× (Gated Attention → MoE)] - Context Window: 262,144 tokens (native), extensible to 1,010,000 tokens
- Vocabulary Size: 248,320 (Expanded for multilingual efficiency)
- Hidden Dimension: 4096
The "Gated DeltaNet" Advantage
By integrating Gated Delta Networks, a form of linear attention, Qwen3.5 significantly optimizes memory usage. In standard 32k context scenarios, decoding throughput is 8.6x higher than the previous Qwen3-Max. For ultra-long context tasks (256k), throughput improves by up to 19x, with a reported 60% reduction in deployment VRAM usage.
Native Multimodal Capabilities
Unlike previous generations that stitched vision encoders onto text models, Qwen3.5 is natively multimodal. It was trained from scratch on a massive dataset of interleaved text, image, and video tokens.
This "early fusion" approach allows Qwen3.5 to "see" the world more like a human does.
- Video Understanding: With a 1M token context, the model can process and analyze up to 2 hours of continuous video.
- Visual Coding: It can interpret hand-drawn UI sketches and generate functional frontend code directly.
- Spatial Reasoning: The model demonstrates improved performance in robotics planning and spatial analysis tasks.
Benchmark Performance
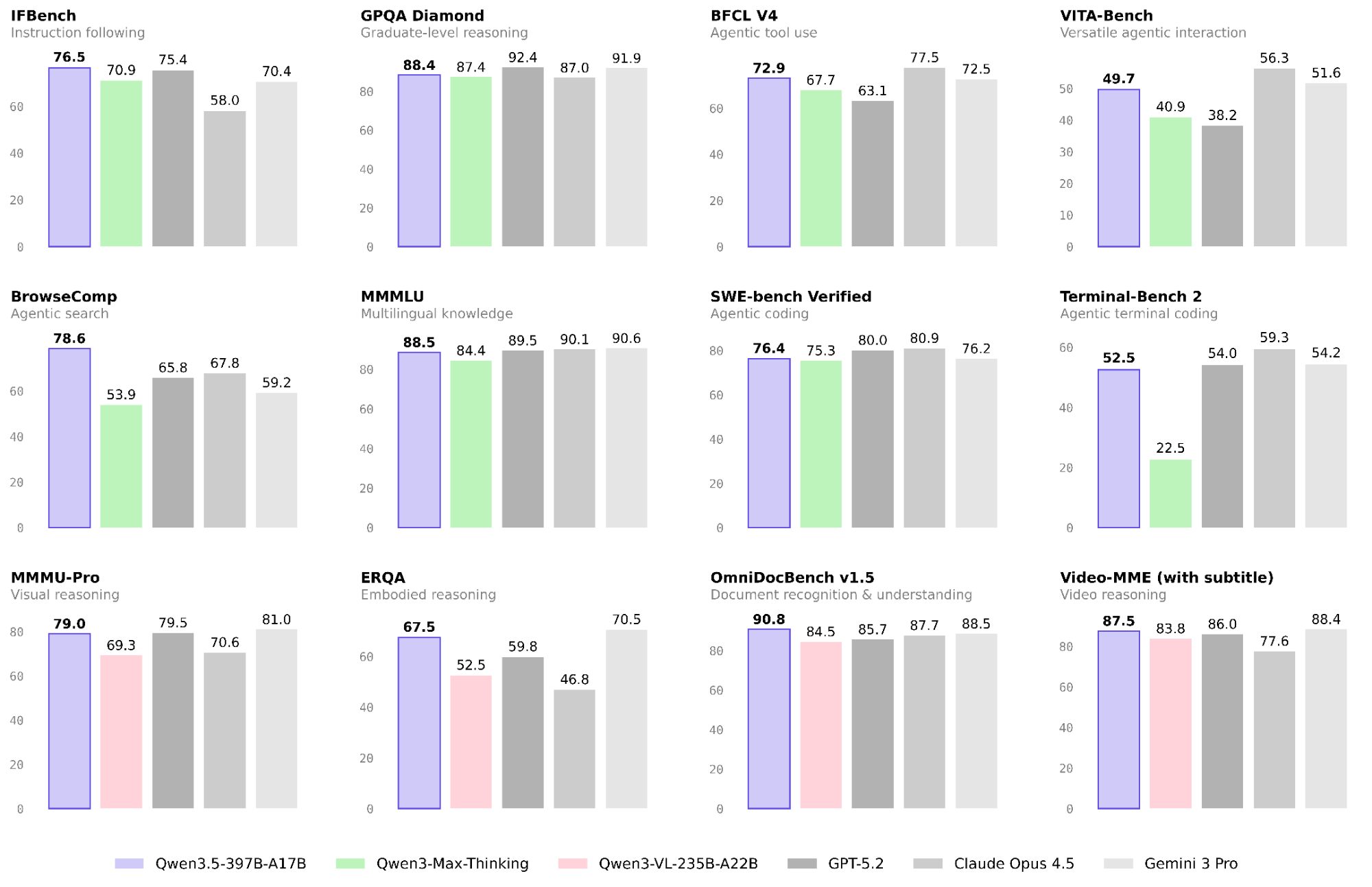
The Qwen Team has released extensive comparison data. Qwen3.5 consistently achieves parity with, and often surpasses, proprietary frontier models.
Language & Reasoning
In pure logic and knowledge tasks, the efficient 17B activated parameters hold their own against massive dense models.
| Benchmark | Qwen3.5 (397B-A17B) | GPT-5.2 | Claude 4.5 Opus | Gemini-3 Pro |
|---|---|---|---|---|
| MMLU-Pro (Knowledge) | 87.8 | 87.4 | 89.5 | 89.8 |
| GPQA (STEM) | 88.4 | 92.4 | 87.0 | 91.9 |
| IFBench (Instruction) | 76.5 | 75.4 | 58.0 | 70.4 |
| LiveCodeBench v6 | 83.6 | 87.7 | 84.8 | 90.7 |
Vision-Language & Agents
This is where Qwen3.5 truly shines, particularly in agentic workflows and visual reasoning.
| Benchmark | Qwen3.5 (397B-A17B) | Qwen3-VL | Gemini-3 Pro |
|---|---|---|---|
| MathVision | 88.6 | 74.6 | 86.6 |
| RealWorldQA | 83.9 | 81.3 | 83.3 |
| OmniDocBench 1.5 | 90.8 | 88.5 | 88.5 |
| BFCL-V4 (General Agent) | 72.9 | 67.7 | 72.5 |
Note: Benchmark data sourced from the official Qwen3.5 release blog, February 2026.
Reinforcement Learning & Agents
Qwen3.5 has been fine-tuned using a scalable asynchronous Reinforcement Learning (RL) framework. The model was trained across millions of agent environments, learning to plan, use tools, and correct its own errors.
This makes Qwen3.5 highly effective for:
- Computer Control: Automating tasks across desktop and mobile operating systems (OSWorld).
- Web Research: Autonomously browsing, filtering, and summarizing complex topics.
- "Vibe Coding": Working seamlessly with IDE agents like Qwen Code to iterate on software projects using natural language.
Global Accessibility: 201 Languages
In a push for inclusivity, Qwen3.5 supports 201 languages and dialects. The vocabulary expansion to ~250k tokens improves encoding efficiency for low-resource languages by 10–60%, making it a truly global foundation model. Qwen 3.5-Plus performs strongly in core benchmarks such as inference, programming, and agent performance, with significantly reduced deployment costs and greatly improved inference efficiency compared to its predecessor. As a fully open-source Apache 2.0 model that can be downloaded locally, its cost-effectiveness is truly exceptional.
Deployment Guide
Developers can access Qwen3.5 immediately via open weights or managed APIs.
Open Source Deployment
The weights are available on Hugging Face and ModelScope. Due to the MoE architecture, using the latest versions of inference engines is recommended.
Using vLLM (Recommended for Production):
vllm serve Qwen/Qwen3.5-397B-A17B \
--port 8000 \
--tensor-parallel-size 8 \
--max-model-len 262144 \
--reasoning-parser qwen3
Using SGLang:
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-397B-A17B \
--tp-size 8 \
--context-length 262144
Managed API (Qwen3.5-Plus)
For those preferring a managed solution, Qwen3.5-Plus is available on Alibaba Cloud Model Studio. It features the "Thinking Mode" by default and costs approximately 0.8 RMB per million tokens, which is 1/18th of that of the Gemini 3 Pro, making it highly cost-effective for scaling.
Conclusion
Qwen3.5 is more than just an upgrade; it is a validation of efficient, hybrid architectures. By delivering frontier-class intelligence with a 17B active parameter footprint, the Qwen Team has lowered the barrier to entry for advanced AI.
Whether you are building complex multimodal agents, analyzing long-form video, or deploying multilingual applications, Qwen3.5 offers a robust, open-source foundation. We look forward to seeing the innovations the community will build on top of this impressive release.
🔗Dive in
GitHub: https://github.com/QwenLM/Qwen3.5
Chat: https://chat.qwen.ai
API:https://modelstudio.console.alibabacloud.com/ap-southeast-1/?tab=doc#/doc/?type=model&url=2840914_2&modelId=group-qwen3.5-plus
Qwen Code: https://github.com/QwenLM/qwen-code
Hugging Face: https://huggingface.co/collections/Qwen/qwen35
ModelScope: https://modelscope.cn/collections/Qwen/Qwen35
blog: https://qwen.ai/blog?id=qwen3.5
For more details, visit the Official Qwen GitHub or the Hugging Face Collection.