
Grok Imagine Video 1.5 プロンプトガイド:ベストプラクティス、公式、実例集(2026年版)
日付: 2026年6月4日(更新版)
著者: Jsam(Klingaio テクニカルエキスパート)
AI生成メディアの次なる進化へようこそ。2026年初頭はKling AI 3.0のような無音物理モデルが主流でしたが、xAIによるGrok Imagine Video 1.5の登場により、動画制作の方法は大きく変わりました。
私たちはもはや無音のフレームを指示するだけではありません。完全なオーディオビジュアル・シンフォニーを指揮しているのです。
Grok Imagine 1.5のネイティブマルチモーダルオーディオにより、動画トークンと音声波形が単一の推論パスで同時処理されます。つまり、フォーリー効果、台詞、環境音、物理動作がタイムライン上で直接同期されるのです。
徹底的なマルチモーダルテストとコミュニティ出力のキュレーションを経て、最高のGrok Imagine 1.5 プロンプトガイドを作成しました。本チュートリアルでは、正確な公式、トラブルシューティングのワークフロー、コピー&ペーストで使える実例を提供し、この新世代のオーディオビジュアルAI動画を習得するお手伝いをします。これらのプロンプト技法は、当社のGrok Imagine 1.5 動画生成器で直接テストできます。

パラダイムシフト:説明ではなく動きに焦点を当てる
クリエイターがテキストから動画モデルからGrok Imagine 1.5(これは厳密には画像から動画エンジン)に移行する際に最もよくある間違いは、開始画像を再説明することです。
Grok Imagine 1.5の黄金律: モデルはすでにソース画像を見ています。画像に何が写っているかを伝えるのではなく、写っているものがどのように動き、相互作用し、音を発するべきかを伝えなさい。
Grok Imagine Video 1.5は画像から動画(I2V)エンジンとして動作するため、動画の品質は開始画像に依存します。アニメーションを開始する前に、GPT Image 2のような高度な画像生成器を使用して、非常に詳細でフォトリアリスティックな開始フレームを作成することを強くお勧めします。
モデルの中核機能:
- ワンパス同期フォーリー効果: ガラスの破砕、雨の打ちつけ、エンジンの轟音が、画面上のアクションと正確に同期して発生します。
- 環境音響: モデルは空間音響(例:タイル貼りの浴室と開けた森の残響の違い)を理解します。
- 音声とトーンの制御: キャラクターの話し方、ささやき、劇的な間を指定できます。
- 15秒の連続性: シングルパスで最大15秒の高忠実度720p映像(24fps)をレンダリング可能(ただし、視覚的安定性のスイートスポットは5〜8秒程度)。
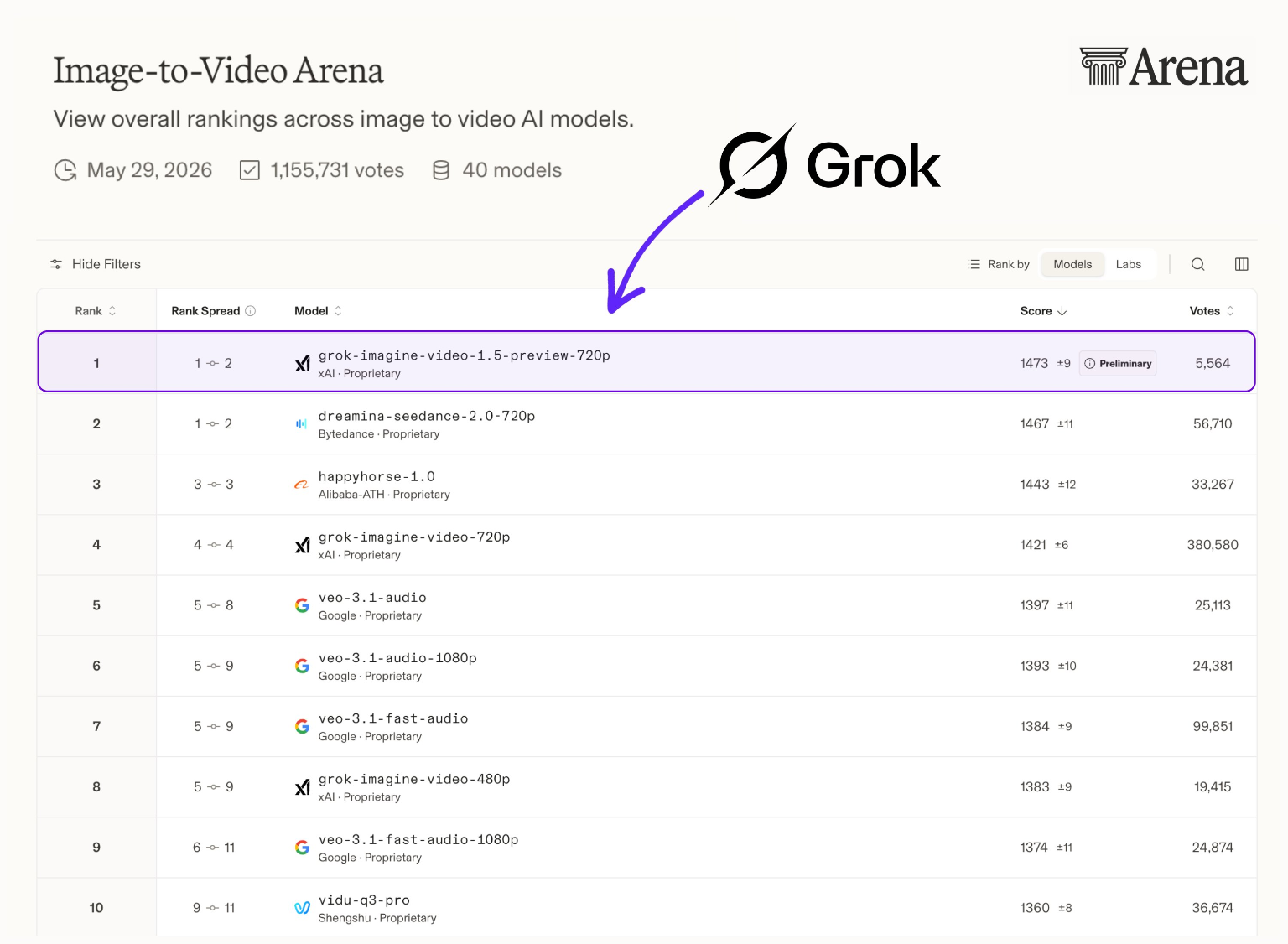
リーダーボード注記: Grok Imagine Video 1.5 Previewは現在、Arena AI 画像から動画リーダーボードで第1位にランクインしており、ネイティブオーディオ機能に対する優れたユーザー評価を示しています。
マスターの公式:Grok Imagine Video 1.5 プロンプトの構成
Grok Imagine Video 1.5を最大限に活用するには、プロンプトの末尾に公式の AUDIO: パラメータを使用して、視覚的な動きと音声キューを分離します。
非構造化タグの積み重ね(「epic, 8K, cinematic」など)は避けてください。モデルはこれらをほとんど無視します。代わりに、以下の階層的なロジックで入力を構成します。
[被写体の動き + 強度修飾子] + [カメラワークとショットタイプ] + [照明と雰囲気の変化] + AUDIO:[環境音、アクションフォーリー、台詞指示]
🏆 注目のスニペット:弱いプロンプト vs 強いプロンプト
モデルは音声と動画を同時に生成するため、弱いプロンプトでは汎用的で同期の取れていない効果音になります。プロンプトを最適化する方法を以下に示します。
| 要素 | 弱いプロンプト(使用しないで) | 強い Grok Imagine 1.5 プロンプト(これを使用) |
|---|---|---|
| 視覚的アクション | 作業場で熱い金属を加工する鍛冶屋。 | 鍛冶屋が重い鉄のハンマーを真っ赤に光る金属に巨大な力で叩きつけ、明るい火花が四方に飛び散る。 |
| カメラ | ズームイン | ゆっくりとした緊張感のあるマクロ・ドリインショットで、ハンマーの打撃点に焦点を当てる。 |
| 音声 | Sound: blacksmith noises | AUDIO: ハンマーの大きな金属的なリズミカルな音、鉄の焼ける音、背景で炉の火が轟く深いうなり声。 |
| 音響 | リアルな音声 | レンガ壁の作業場に反響するハンマーの打撃音の深い残響。 |
Grok Imagine Video 1.5 上級プロンプト例5選(すぐに使える)
以下は、Grok Imagine Video 1.5のネイティブオーディオビジュアルロジックを活用するために設計された5つの最適化プロンプトテンプレートです。GPT Image 2を使用して開始フレームを生成し、これらのプロンプトを当社のGrok Imagine 1.5 ウェブアプリに入力してください。
1. シネマティックフォーリー効果と大気物理
目標: 物理的衝撃のフレーム正確なオーディオビジュアル同期を達成する。
スローモーション、マクロ追跡ショット。錆びたパイプから水滴が水たまりに滴り落ちる。各水滴が水面に衝突し、同心円状の波紋を作る。
AUDIO: 深く空洞のある滴る音、高音の滴りを伴う柔らかな水しぶき、遠くで雷雨の低い轟音が反響する。
- なぜ機能するか: 物理的な衝撃(「水滴が水面に衝突」)を非常に具体的な音の形容詞(「空洞のある滴る音」「柔らかな水しぶき」)と共に記述することで、モデルが音声波形を対応する動画フレームに結びつけるように導く。
入力画像(開始フレーム):

生成動画(ネイティブオーディオ付き):
2. キャラクターの台詞と声優演技
目標: 正確な口の動きを伴うネイティブ音声合成の活用。
探偵がゆっくりと頭を右に向け、カメラに直接語りかける。手持ちカメラの微妙な揺れが緊張感を高める。
AUDIO: 静かでかすれたささやき声:「やったぞ。でも時間が迫っている。」 背景にかすかな紙の擦れる音、低い時計の秒針の音。
- なぜ機能するか: 台詞入力を
AUDIO:ブロック内に標準化することで、Grok Imagine 1.5がボーカルトラックを分離し、視覚的なアニメーションに干渉せずに唇の動きを自然に同期させる。
3. 触感を重視したコマーシャル商品フォーカス
目標: 安定したテキストとエレガントな環境音の表示。
エスプレッソカップが台座上で滑らかに回転し、カメラは目の高さで軌道を描く。暖かなゴールデンアワーの光が大理石のカウンタートップの表面を撫でる。
AUDIO: 高圧の蒸気のシュー音、熱いエスプレッソがカップに一定に滴る音、陶器の優しいカチカチ音、柔らかなバックグラウンドジャズ。
- なぜ機能するか: 高級感のある視覚的商品レンダリングと環境音を組み合わせて、完全な感覚的広告を創り出す。ロゴやテキストの完全な保存が絶対条件の厳格なコマーシャル用途では、詳細保存に優れたByteDanceのSeedance 2.0と結果を比較テストすることもできる。
入力画像(開始フレーム):

生成動画(ネイティブオーディオ付き):
4. サスペンスフルなSFアクション(ダイナミックオーディオ)
目標: ハイテクカメラワークと同期した重い機械音の生成。
宇宙船の狭く暗い金属製通路を織り抜けるFPVドローンショット。赤い緊急警報灯がリズミカルに点滅する。重い鋼鉄の防爆扉がゆっくりと閉まる。
AUDIO: 重い鋼鉄の扉が滑る時の大きく深い機械的な軋み音、サイレンの鳴り響き、宇宙船の原子炉コアの低周波ハム音。
- なぜ機能するか: 高速カメラワークと重く軋む機械音の組み合わせにより、モデルが大きな効果音を高速で動く環境オブジェクトと同期させる能力が試される。
5. マルチショット・ナラティブと連続性(15秒のベストプラクティス)
目標: 特定の秒数で正確なハードカットを強制し、音声タイムラインを遷移させる。
(0-3秒) 柔らかな冬の吹雪の中、雪の松林に佇む静かなコテージの広角導入ショット。
(3-7秒) 素朴な石造りの暖炉とパチパチと燃える薪の内部クローズアップショットにカット。その後、手がゆっくりと蒸気の立つ熱いお茶を木製のマグカップに注ぐ。
(7-12秒) コテージの居心地の良い窓から降る雪を眺め、優しく微笑む人物の肩越しショットにカット。艶やかで、暖かく、シネマティック。
AUDIO: (0-3秒) 外のこもった冬風の唸り、(3-7秒) 暖炉のはっきりしたパチパチ音と柔らかな液体の注ぐシュー音、(7-12秒) 優しいアコースティックギターのメロディーと満足げな小さなため息。
- なぜ機能するか:
(0-3秒)や(3-7秒)のように正確な時間マーカーを指定することで、トランスフォーマーエンジンにシーンカットをいつトリガーし、音響をいつ切り替えるかを正確に指示する。これにより、異なるショットが混ざったり「モーフィング」するという古典的なAIエラーを防ぐ。
入力画像(開始フレーム):

生成動画(ネイティブオーディオ付き):
トラブルシューティング:Grok Imagine 1.5 の一般的なアーティファクト修正
ネイティブのオーディオビジュアル生成でも、マルチモーダルパイプラインには問題が発生する可能性があります。最も一般的なエラーのトラブルシューティング方法は以下の通りです。
1. スローモーションや動きの鈍さを修正する方法
- 問題: Grok Imagine 1.5はデフォルトで非常にシネマティックでゆっくりとした動きを生成します。素早い物理的アクション(格闘技やスポーツなど)が鈍く感じられる場合があります。
- 解決策: モデルは強度修飾子に強く反応します。高速で動く動きを強制するために、具体的で高速度の動詞と副詞を使用します。「車が通過する」ではなく「車が高速で疾走する」と書きましょう。「翼が羽ばたく」ではなく「翼が大きな振幅で羽ばたく」と書きましょう。非常にスタイライズされた漫画や超高速アニメーションのワークフローには、Nano Banana Proのような軽量で専門的なパイプラインも検討できます。
2. ネガティブプロンプトは使用しない
- 問題: 「deformed, extra fingers, text morphing」のようなネガティブプロンプトを入力して視覚エラーを修正しようとしても、出力が変わりません。
- 解決策: Grok Imagine 1.5はネガティブプロンプトを無視します。 モデルに「何をすべきでないか」を伝えるのではなく、見たい正の状態を説明することに集中してください。
3. テキストとロゴのモーフィングを修正する方法
- 問題: Grok Imagine 1.5は流動的でシネマティックなシーンに最適化されているため、ボトルやパッケージの小さなテキストがカメラ回転中にずれる可能性があります。
- 解決策: 厳格なブランド一貫性が必要なeコマースや製品キャンペーンを実行している場合は、詳細保存に優れたSeedance 2.0と結果を比較するか、複雑な視覚的一貫性のためにKling 3.0を使用してみてください。
結論:無音動画のレンダリングはやめよう
無音のAI動画の時代は終わりつつあります。Grok Imagine Video 1.5のデュアルプロンプト構造を習得することで、ポストプロダクションを大幅に減らした、完全で感覚豊かな15秒のシーケンスを生成できます。
Grok Imagine Video 1.5をマスターする鍵は、音を視覚物理の積極的な参加者として扱うことです。これらの公式を試し、GPT Image 2で開始フレームを生成し、今すぐGrok Imagine 1.5 生成器で完全で高忠実度の動画を直接作成し始めましょう。また、別の生成オプションを探したい場合は、メインのKlingaioホームに戻ることもできます。
よくある質問(FAQ)
Q: Grok Imagine 1.5はテキストから動画に対応していますか? A: いいえ、現行バージョンは厳密に画像から動画(I2V)モデルです。生成を導くために開始画像をアップロードする必要があります。ネイティブで動きの多いテキストから動画には、Kling 3.0をご利用いただけます。
Q: Grok Imagine Video 1.5の生成可能な最大長は? A: モデルはネイティブで1秒から15秒の生成に対応し、24fpsでレンダリングします。5~8秒が視覚的安定性のスイートスポットとされています。
Q: Grok Imagine Video 1.5でオーディオ生成を無効にできますか?
A: はい。プロンプトに AUDIO: パラメータや音の説明を含めなければ、モデルは標準的な無音のMP4ファイルを出力します。
Q: Grok Imagine 1.5の無料トライアルはありますか? A: はい。当社のウェブアプリケーション/grok-imagine/grok-imagine-15でGrok Imagine 1.5を直接テストし、動画を生成できます。