
Grok Imagine Video 1.5 Prompt-Guide: Best Practices, Formeln & Beispiele (2026)
Datum: 4. Juni 2026 (Aktualisiert)
Autor: Jsam (Klingaio Technikexperte)
Willkommen zur nächsten Entwicklungsstufe KI-generierter Medien. Während das frühe Jahr 2026 von stillen Physikmodellen wie Kling AI 3.0 geprägt war, hat die Einführung von Grok Imagine Video 1.5 von xAI einen großen Wandel in der Videoproduktion eingeleitet.
Wir lenken nicht länger nur stumme Bilder; wir dirigieren eine vollständige audiovisuelle Symphonie.
Mit der nativen multimodalen Audiofunktion von Grok Imagine 1.5 werden Video-Token und Audio-Wellenformen in einem einzigen Inferenzdurchgang gemeinsam verarbeitet. Dadurch werden Foley-Effekte, Dialoge, Umgebungsgeräusche und physische Bewegungen direkt auf der Timeline synchronisiert.
Nach umfangreichen multimodalen Tests und der Kuratierung von Community-Ergebnissen haben wir den ultimativen Grok Imagine 1.5 Prompt-Guide entwickelt. Dieses Tutorial liefert die exakten Formeln, Fehlerbehebungs-Workflows und Copy-Paste-Beispiele, um diese neue Generation von audiovisueller KI-Videoproduktion zu meistern. Du kannst diese Prompting-Techniken direkt auf unserem Grok Imagine 1.5 Videogenerator testen.

Paradigmenwechsel: Fokus auf Bewegung, nicht auf Beschreibung
Einer der häufigsten Fehler, den Kreative beim Umstieg von Text-zu-Video-Modellen auf Grok Imagine 1.5 (das ausschließlich ein Bild-zu-Video-Modell ist) machen, ist die erneute Beschreibung des Startbildes.
Die goldene Regel von Grok Imagine 1.5: Das Modell sieht bereits dein Quellbild. Sag ihm nicht, was auf dem Bild zu sehen ist, sondern sag ihm, wie sich das, was auf dem Bild ist, bewegen, interagieren und klingen soll.
Da Grok Imagine Video 1.5 als Bild-zu-Video (I2V)-Engine arbeitet, hängt die Qualität deines Videos stark vom Ausgangsbild ab. Wir empfehlen dringend, einen fortschrittlichen Bildgenerator wie GPT Image 2 zu verwenden, um einen hochdetaillierten, fotorealistischen Startframe zu erstellen, bevor du mit der Animation beginnst.
Kernfunktionen des Modells:
- Ein-Durchgang-synchronisierte Foley-Effekte: Glassplitter, Trommeln von Regen oder Motorgeräusche treten präzise zum Zeitpunkt der gezeigten Aktion auf.
- Raumakustik: Das Modell versteht räumliche Akustik (z. B. den Hallunterschied zwischen einem gefliesten Badezimmer und einem offenen Wald).
- Stimm‑ und Tonkontrolle: Lege Sprechstile der Charaktere, Flüstern oder dramatische Pausen fest.
- 15‑Sekunden-Kontinuität: Erstelle bis zu 15 Sekunden hochauflösendes 720p-Material mit 24 fps in einem Durchgang (wobei der 5‑bis 8‑Sekunden-Bereich der optimale Kompromiss für visuelle Stabilität bleibt).
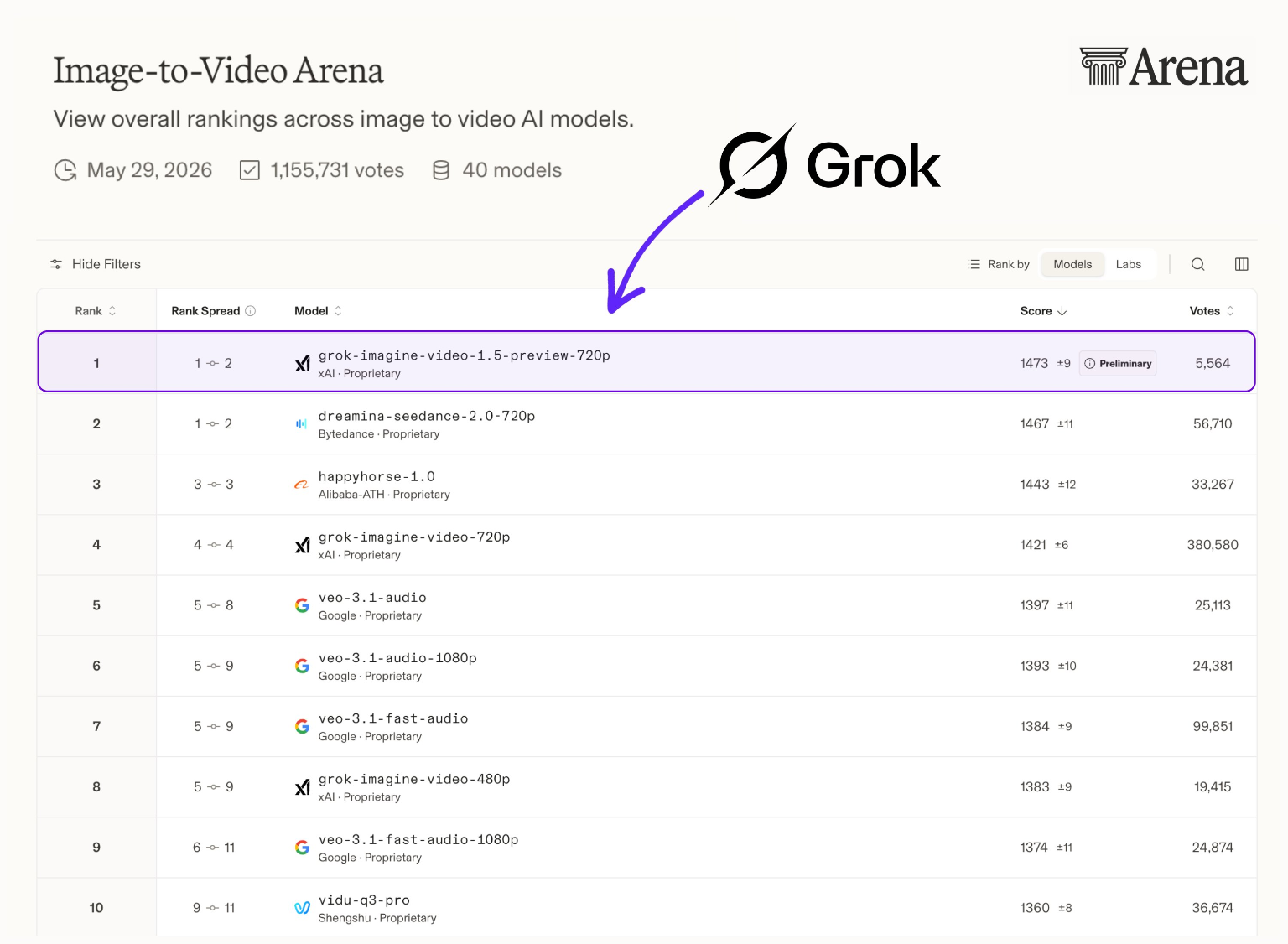
Hinweis zur Rangliste: Grok Imagine Video 1.5 Preview belegt derzeit Platz 1 auf dem Arena AI Image-to-Video Leaderboard und zeigt eine hervorragende Präferenz der Nutzer für seine nativen Audiofunktionen.
Die Master-Formel: Strukturierung deines Grok Imagine Video 1.5 Prompts
Um das Beste aus Grok Imagine Video 1.5 herauszuholen, trennen wir die visuelle Bewegung von den Audiohinweisen, indem wir den offiziellen AUDIO:‑Parameter am Ende des Prompts verwenden.
Vermeide unstrukturierte Tag-Stapel (wie „episch, 8K, filmisch“), die das Modell weitgehend ignoriert. Strukturiere stattdessen deine Eingaben nach dieser logischen Schichtung:
[Subjektbewegung + Intensitätsmodifikatoren] + [Kamerabewegung & Aufnahmeart] + [Licht- & Atmosphärenänderungen] + AUDIO: [Umgebungsgeräusche, Aktions-Foley, Dialoganweisungen]
🏆 Ausgewählter Ausschnitt: Schwache vs. starke Prompts
Da das Modell Audio und Video gleichzeitig generiert, führt ein schwacher Prompt zu generischen, unsynchronen Soundeffekten. So optimierst du deine Prompts:
| Element | Schwacher Prompt (Nicht verwenden) | Starker Grok Imagine 1.5 Prompt (Verwenden) |
|---|---|---|
| Visuelle Aktion | Ein Schmied arbeitet in einer Werkstatt an heißem Metall. | Der Schmied schwingt einen schweren Eisenhammer mit großer Wucht auf das glühende orangefarbene Metall nieder, sodass helle Funken nach außen fliegen. |
| Kamera | Heranzoomen | Langsame, angespannte Makro-Heranfahrt (Dolly-in) auf den Auftreffpunkt des Hammers. |
| Audio | Sound: Schmiedegeräusche | AUDIO: lautes, rhythmisches metallisches Klirren eines Hammers, zischendes Eisen, tiefes, brausendes Fauchen des Schmiedefeuer im Hintergrund. |
| Akustik | Realistischer Ton | Tiefer Nachhall der Hammerschläge, die in einer Backsteinwerkstatt widerhallen. |
5 fortgeschrittene Grok Imagine Video 1.5 Prompt-Beispiele (gebrauchsfertig)
Im Folgenden findest du fünf optimierte Prompt-Vorlagen, die die native audiovisuelle Logik von Grok Imagine Video 1.5 nutzen. Erstelle deinen Startframe mit GPT Image 2 und gib diese Prompts dann in unsere Grok Imagine 1.5 Web-App ein.
1. Filmischer Foley & atmosphärische Physik
Ziel: Frame-genaue audiovisuelle Synchronisation physikalischer Stöße.
Zeitlupen-Makro-Tracking-Shot von Wassertropfen, die von einem rostigen Rohr auf eine Wasserpfütze tropfen. Jeder Tropfen trifft auf die Wasseroberfläche und erzeugt konzentrische Ringe.
AUDIO: tiefe, hohle Tropfgeräusche, weiches Wasserplätschern mit hohen Tropfen, entferntes tiefes Grollen eines Gewitters, das draußen widerhallt.
- Warum es funktioniert: Die Beschreibung des physikalischen Aufpralls („Tropfen trifft auf die Wasseroberfläche“) zusammen mit hochspezifischen Klangadjektiven („hohler Tropf“, „weiches Plätschern“) leitet das Modell an, die Audio-Wellenform mit dem entsprechenden Videoframe zu verknüpfen.
Eingabebild (Startframe):

Generiertes Video (mit nativer Audio):
2. Charakterdialog & Sprachausgabe
Ziel: Nutzung der nativen Sprachsynthese mit präziser Lippenbewegung.
Der Detektiv dreht langsam den Kopf nach rechts und spricht direkt in die Kamera, ein subtiles Handkamera-Wackeln erhöht die Spannung.
AUDIO: ein leises, kratziges Flüstern: „Wir haben es geschafft. Aber die Zeit läuft.“ Leises Rascheln von Papier im Hintergrund, leises Ticken einer Uhr.
- Warum es funktioniert: Die Standardisierung der Dialogeingabe innerhalb des
AUDIO:-Blocks hilft Grok Imagine 1.5, die Sprachspur zu isolieren und die Lippenbewegungen natürlich zu synchronisieren, ohne die visuelle Animation zu beeinträchtigen.
3. Taktiler Werbe-Produktfokus
Ziel: Stabile Textdarstellung mit eleganter Umgebungsaudio.
Die Espressotasse dreht sich gleichmäßig auf dem Sockel, die Kamera umkreist sie auf Augenhöhe, warmes goldenes Stundenlicht streicht über die Oberfläche der Marmorarbeitsplatte.
AUDIO: Zischen von Dampf unter hohem Druck, heißer Espresso tropft gleichmäßig in die Tasse, sanftes Klirren von Porzellan, leiser Hintergrund-Jazz.
- Warum es funktioniert: Es kombiniert hochwertiges visuelles Produktrendering mit Umgebungsgeräuschen zu einem vollständigen Sinneserlebnis. Für strenge kommerzielle Anwendungen, bei denen absolute Konservierung von Logos und Text erforderlich ist, kannst du deine Ergebnisse mit ByteDances Seedance 2.0 vergleichen.
Eingabebild (Startframe):

Generiertes Video (mit nativer Audio):
4. Spannungsgeladene Sci-Fi-Action (dynamische Audio)
Ziel: Erzeugung massiver mechanischer Geräusche, synchronisiert mit High-Tech-Kamerabewegungen.
FPV-Drohnenflug durch einen engen, dunklen Metallkorridor eines Raumschiffs. Rote Notfallwarnlichter blinken rhythmisch. Eine schwere Stahltür gleitet langsam zu.
AUDIO: lautes, tiefes mechanisches Mahlen der schweren Stahltür, heulende Warnsirenen, tiefes Brummen eines Raumschiffreaktorkerns.
- Warum es funktioniert: Die schnelle Kamerabewegung gepaart mit schweren, knirschenden mechanischen Geräuschen testet die Fähigkeit des Modells, laute Soundeffekte mit sich schnell bewegenden Umgebungsobjekten zu synchronisieren.
5. Mehrere Einstellungen & Kontinuität (15‑Sekunden-Best-Practice)
Ziel: Erzwingen präziser harter Schnitte zu bestimmten Sekunden bei gleichzeitigem Übergang der Audio-Timeline.
(0-3s) Weite Einstellung einer ruhigen Hütte in einem verschneiten Kiefernwald während eines sanften Wintersturms.
(3-7s) Schnitt zu einer Innen-Nahaufnahme eines rustikalen Kamins aus Naturstein mit knisterndem Brennholz; dann gießt eine Hand langsam dampfenden heißen Tee in einen Holzbecher.
(7-12s) Schnitt zu einer Über-die-Schulter-Aufnahme einer Person, die aus dem gemütlichen Hüttenfenster auf den fallenden Schnee blickt und sanft lächelt. Glänzend, warm, filmisch.
AUDIO: (0-3s) gedämpftes Heulen des Winterwinds draußen, (3-7s) klares Knistern des Kamins und ein leises Zischen des eingegossenen Getränks, (7-12s) sanfte akustische Gitarrenmelodie und ein leises zufriedenes Seufzen.
- Warum es funktioniert: Die Angabe exakter Zeitmarken wie
(0-3s)und(3-7s)teilt der Transformer-Engine genau mit, wann ein Szenenschnitt ausgelöst und wann die Akustik gewechselt werden soll. Dies verhindert den klassischen KI-Fehler des Vermischens oder „Morphens“ verschiedener Aufnahmen.
Eingabebild (Startframe):

Generiertes Video (mit nativer Audio):
Fehlerbehebung: Häufige Grok Imagine 1.5-Artefakte beheben
Selbst bei nativer audiovisueller Generierung können multimodale Pipelines auf Probleme stoßen. So behebst du die häufigsten Fehler:
1. Wie behebt man Zeitlupen- oder träge physikalische Bewegungen?
- Problem: Grok Imagine 1.5 neigt standardmäßig zu sehr filmischen, langsamen Bewegungen. Schnelle physikalische Aktionen (z. B. Kampfsport oder Sport) wirken träge.
- Lösung: Das Modell reagiert stark auf Intensitätsmodifikatoren. Verwende spezifische, hochdynamische Verben und Adverbien, um schnelle Aktionen zu erzwingen. Schreibe statt „Auto vorbeifahren“: „Auto rast mit hoher Geschwindigkeit vorbei“. Statt „Flügelschlagen“: „Flügel schlagen mit großer Amplitude“. Für stark stilisierte Cartoon- oder hyper-schnelle Animations-Workflows kannst du auch leichte, spezialisierte Pipelines wie Nano Banana Pro erkunden.
2. Keine negativen Prompts verwenden
- Problem: Du gibst negative Prompts wie „deformiert, zusätzliche Finger, Text-Morphing“ ein, um visuelle Fehler zu beheben, aber die Ausgabe ändert sich nicht.
- Lösung: Grok Imagine 1.5 ignoriert negative Prompts. Anstatt dem Modell zu sagen, was es nicht tun soll, konzentriere dich darauf, die gewünschten positiven Zustände zu beschreiben.
3. Wie behebt man Text- und Logo-Morphing?
- Problem: Da Grok Imagine 1.5 für flüssige, filmische Szenen optimiert ist, kann kleiner Text auf Flaschen oder Verpackungen während Kameradrehungen verwackeln.
- Lösung: Wenn du E‑Commerce- oder Produktkampagnen mit strenger Markenkonsistenz durchführst, vergleiche deine Ergebnisse mit Seedance 2.0, das sich durch Detailtreue auszeichnet, oder verwende Kling 3.0 für komplexe visuelle Konsistenz.
Fazit: Höre auf, stumme Videos zu rendern
Die Ära des stummen KI-Videos neigt sich dem Ende zu. Indem du die duale Prompting-Struktur von Grok Imagine Video 1.5 beherrschst, kannst du vollständige, sinnesreiche 15‑Sekunden-Sequenzen generieren, die weitaus weniger Nachbearbeitung erfordern.
Der Schlüssel zur Meisterschaft von Grok Imagine Video 1.5 liegt darin, den Ton als aktiven Teilnehmer an deiner visuellen Physik zu behandeln. Probiere diese Formeln aus, erstelle deine Startframes mit GPT Image 2 und beginne noch heute mit der Erstellung vollständiger, hochwertiger Videos direkt auf dem Grok Imagine 1.5 Generator. Oder wenn du andere Generierungsoptionen erkunden möchtest, kehre zu unserer Hauptseite Klingaio Startseite zurück.
Häufig gestellte Fragen (FAQ)
F: Unterstützt Grok Imagine 1.5 Text-zu-Video?
A: Nein, die aktuelle Version ist ausschließlich ein Bild-zu-Video (I2V)-Modell. Du musst ein Startbild hochladen, um die Generierung zu steuern. Für natives, bewegungsreiches Text-zu-Video kannst du Kling 3.0 verwenden.
F: Wie lang kann eine Grok Imagine Video 1.5-Generierung sein?
A: Das Modell unterstützt nativ Generierungen von 1 bis 15 Sekunden bei 24 Bildern pro Sekunde (fps). 5–8 Sekunden gelten allgemein als optimaler Bereich für visuelle Stabilität.
F: Kann ich den Audio-Generator in Grok Imagine Video 1.5 deaktivieren?
A: Ja. Wenn du den AUDIO:-Parameter oder jegliche Geräuschbeschreibungen in deinem Prompt weglässt, gibt das Modell eine Standard-MP4-Datei ohne Ton aus.
F: Gibt es eine kostenlose Testversion für Grok Imagine 1.5?
A: Ja, du kannst Grok Imagine 1.5 direkt in unserer Webanwendung unter /grok-imagine/grok-imagine-15 testen und Videos generieren.