
A Comprehensive Guide to GPT-5.4: The Evolution of the AI Digital Employee
Welcome to the new era of artificial intelligence. On March 5, 2026, OpenAI officially released its latest flagship model, GPT-5.4, and the technology community is already buzzing with excitement. Rather than simply offering a faster or stronger iteration of previous tools, GPT-5.4 represents a fundamental shift in how we interact with machine learning models. We are moving away from simple conversational assistants toward what OpenAI accurately describes as an "Agent system".
In this technical blog post, we will humbly explore the profound updates introduced in GPT-5.4. We will look at its all-in-one architecture, its groundbreaking native computer use capabilities, and the practical implications for developers and businesses alike. If you are curious about how GPT-5.4 might streamline your workflow, we invite you to read on.
The "All-in-One" Capability Integration
Historically, the evolution of large language models followed a path of patching weaknesses one by one. GPT-5.4 changes this narrative completely. For the first time, OpenAI has integrated deep reasoning, advanced programming, native computer usage, deep web search, and a massive million-token context window into a single cohesive model.
What is truly remarkable about GPT-5.4 is that this unified approach does not sacrifice the performance of any individual metric. The model maintains a leading position across multiple critical benchmark tests, proving that efficiency and capability enhancement can indeed happen simultaneously. It is faster, more powerful, and surprisingly cost-effective for complex tasks.
Elevating Deep Knowledge Work
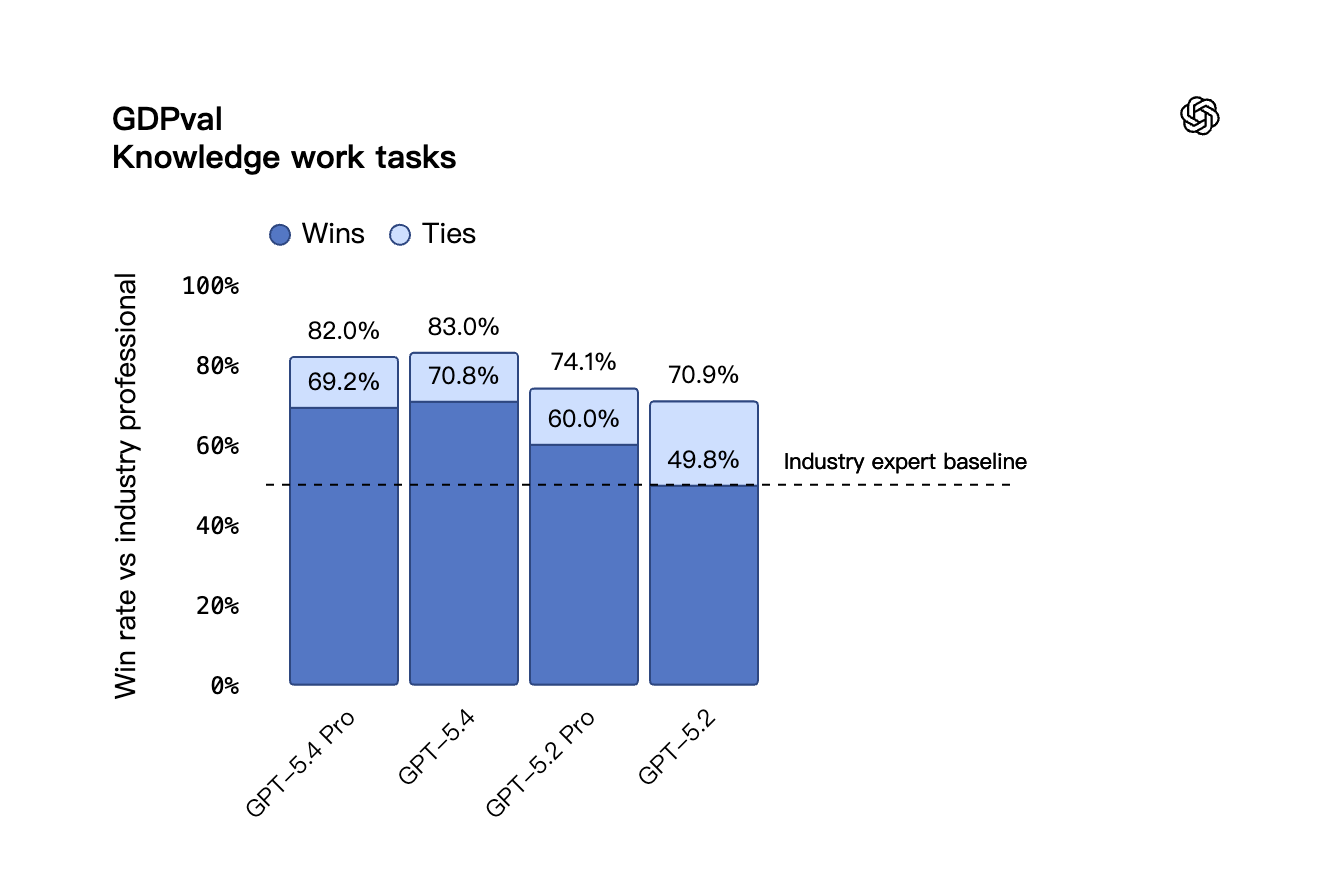
To begin, let us examine how GPT-5.4 handles what we call "Knowledge Work". OpenAI evaluated the model using the GDPval benchmark, which assesses AI performance in real-world professional scenarios covering 44 occupations across the nine industries that contribute most to the United States GDP. This is not a simple question-and-answer test. It requires the model to produce actual work deliverables (like accounting spreadsheets, hospital shift schedules, and even short video content).
In the GDPval benchmark, GPT-5.4 achieved a combined tie and win rate of 83.0%, effectively matching or exceeding the performance of human industry professionals.
When it comes to office documents, the improvements are equally impressive. In an internal investment banking modeling test, the average score for GPT-5.4 reached 87.3% (a significant leap from the 68.4% scored by GPT-5.2). Furthermore, human evaluators preferred the presentations generated by GPT-5.4 over previous versions 68% of the time. They cited a more mature visual design, a clearer structure, and a more logical use of generated images. To bridge the gap between AI and traditional software, OpenAI has also introduced a ChatGPT Excel plugin, allowing corporate users to seamlessly invoke the model directly within their spreadsheets.
The Milestone of Native Computer Use
Perhaps the most fascinating feature that will catch the eyes of developers is the native computer operation capability of GPT-5.4. Unlike earlier systems that required dedicated external agents to interact with a desktop, GPT-5.4 can natively understand software interfaces through screenshots and execute precise mouse clicks and keyboard inputs.
The test results speak volumes:
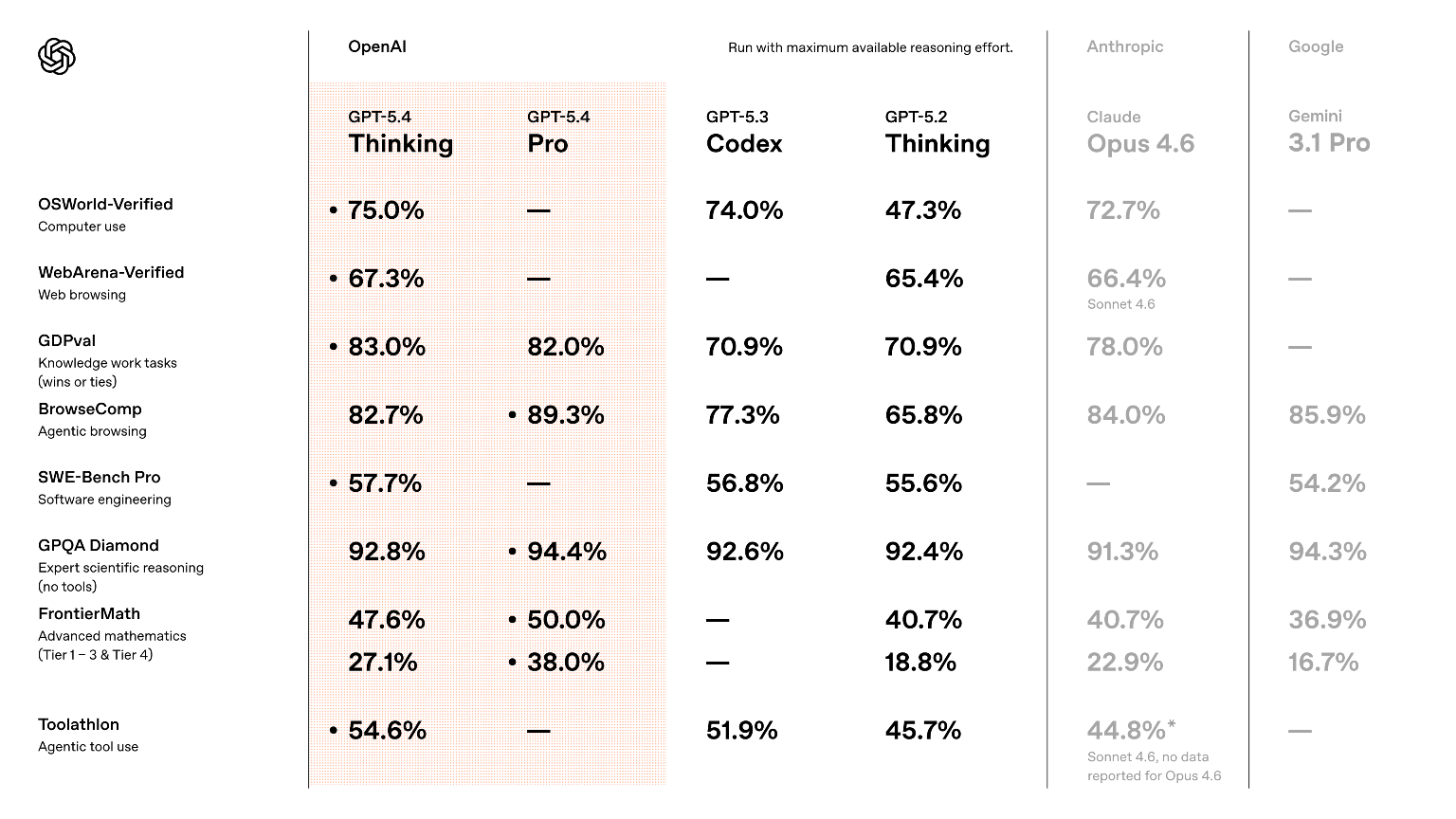
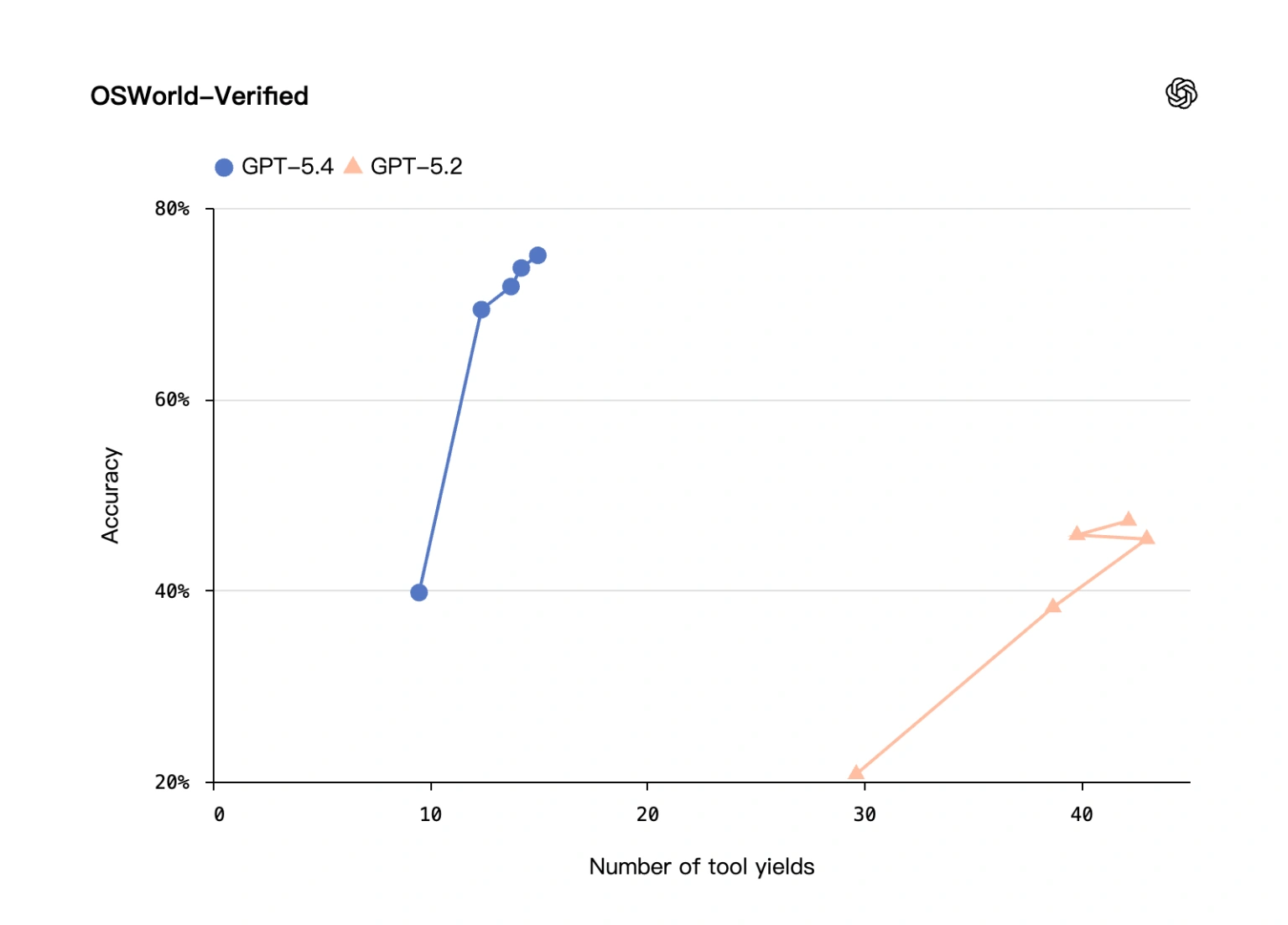
- In the OSWorld-Verified benchmark for desktop operations, GPT-5.4 achieved a 75.0% success rate. This is a monumental achievement because it officially surpasses the human average baseline of 72.4%.
- In the WebArena browser task test, it secured a 67.3% success rate.
- In the Online-Mind2Web test (where the model operates web pages relying solely on screenshot observations), GPT-5.4 reached an astounding 92.8% success rate.
Real-world testing backs up these numbers. The real estate data company Mainstay tested this capability across approximately 30,000 HOA and property tax portals. GPT-5.4 achieved a 95% success rate on the first attempt and a 100% success rate within three attempts. This allowed the tasks to be completed three times faster while reducing token consumption by about 70%. It is clear that GPT-5.4 is setting a new standard for automated workflows and UI interactions.
Advanced Coding and Visual Debugging
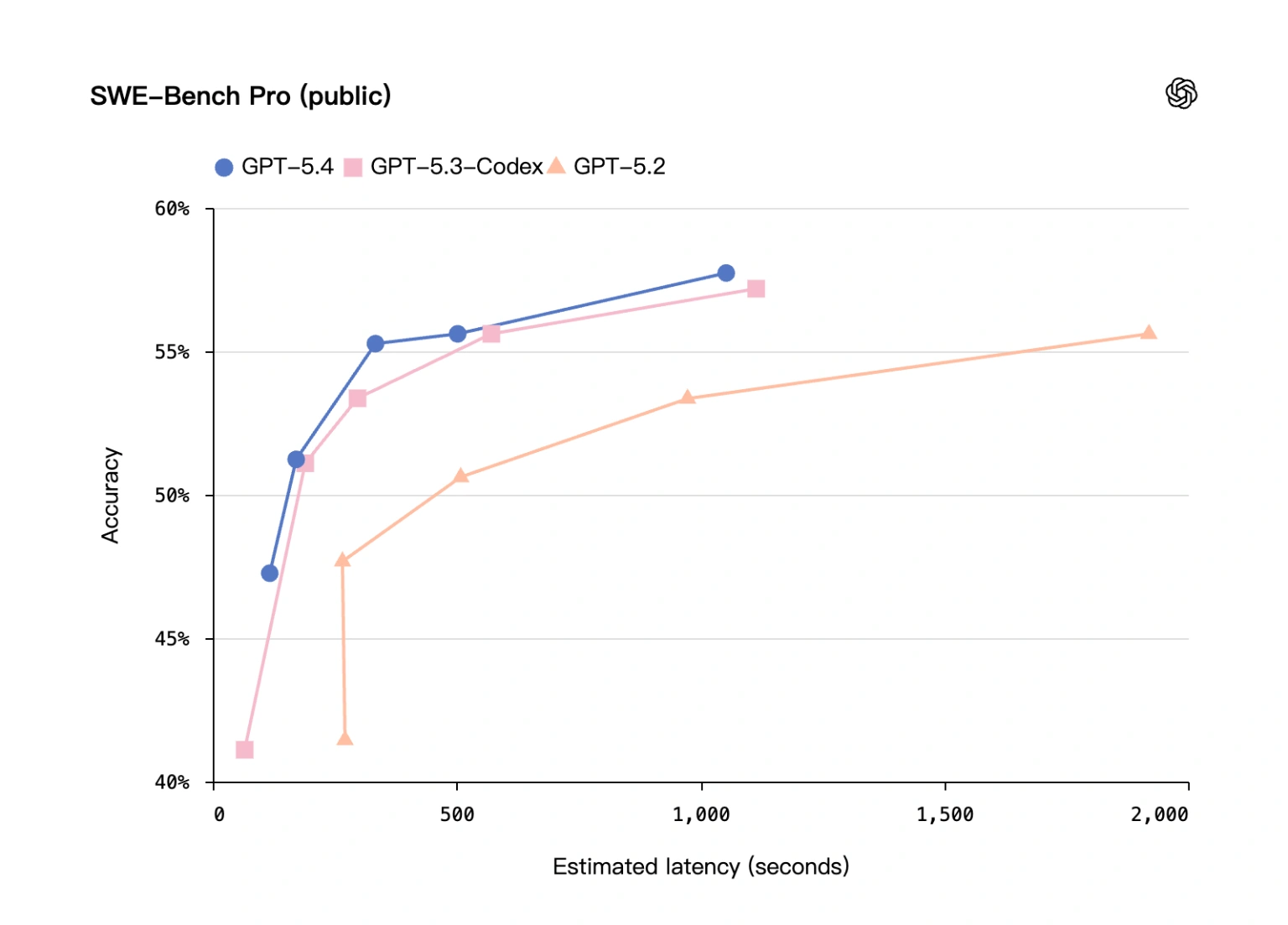
Programming is another pillar where GPT-5.4 shines brightly. It has fully absorbed the capabilities of the previously celebrated GPT-5.3-Codex model. In the SWE-Bench Pro test, GPT-5.4 scored 57.7%, slightly outperforming the 56.8% of GPT-5.3-Codex, while offering lower latency.
Developers will be pleased to know about the "/fast", mode, which increases token output speed by 1.5 times. However, the most innovative addition is an experimental skill called "Playwright (Interactive)". This feature allows the AI to open a window for visual debugging while it writes web applications.
For instance, OpenAI demonstrated GPT-5.4 building a theme park simulation game from a simple prompt. The model generated the art assets, wrote the logic, laid out the paths, and automatically ran browser tests to verify guest behaviors and system metrics. Similarly, an independent developer used GPT-5.4 to code a functional clone of Minecraft in about 24 minutes. This "build and test simultaneously", workflow brings the model incredibly close to the working habits of a senior full-stack human engineer.
Enhanced Vision, Parsing, and Factuality
Alongside its action-oriented skills, GPT-5.4 boasts refined observational talents. In the MMMU-Pro visual reasoning test without external tools, it achieved an 81.2% accuracy rate. When utilizing tools, this number climbed to 82.1%.
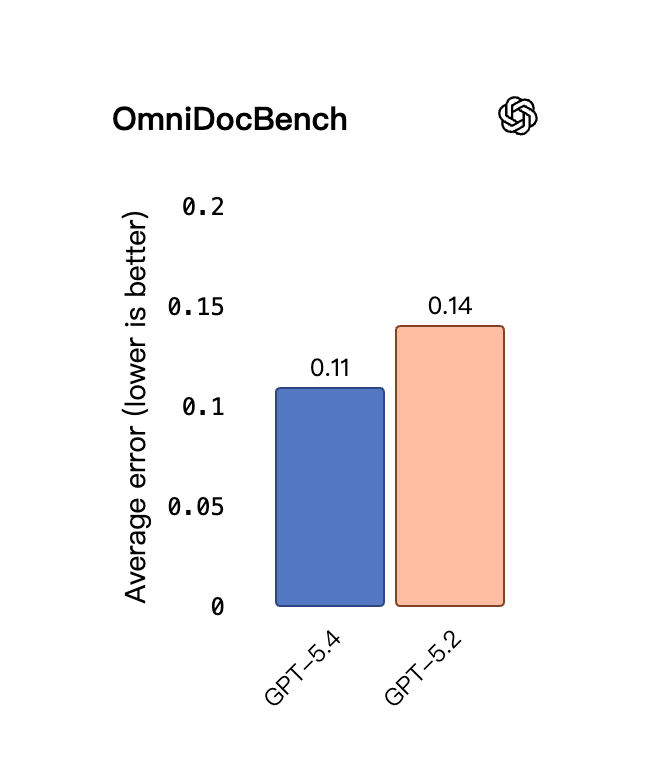
The model now natively supports high-resolution raw image inputs up to 10.24 million pixels (or a maximum edge of 6000 pixels). This high-fidelity vision directly translates to better document parsing. In the OmniDocBench test, its average normalized edit distance error rate dropped from 0.140 to 0.109.
Most comfortingly for enterprise users, GPT-5.4 is a highly factual model. Official introductions indicate that the probability of factual errors (often known as AI hallucinations) has decreased by 33% compared to previous generations. This makes GPT-5.4 a much more reliable partner for critical business research.
Efficiency, Pricing, and the Tool Search Mechanism
One of the most practical engineering updates in GPT-5.4 is the introduction of a "Tool Search", mechanism. In the past, if you wanted an AI to access company databases or external APIs, you had to load all tool definitions into the prompt. If you had dozens of tools, this caused a massive token explosion.
GPT-5.4 solves this by querying a brief list of tools and only retrieving the detailed definitions of the ones it actually needs. In the MCP Atlas benchmark experiments, this dictionary-like lookup mechanism reduced total token usage by a massive 47% while maintaining the exact same accuracy. In the Toolathlon benchmark (which requires multi-step operations like reading attachments and scoring assignments), GPT-5.4 scored 54.6%. For tasks requiring continuous web searching to gather hard-to-find information, the BrowseComp test showed GPT-5.4 reaching 82.7%, with the specialized GPT-5.4 Pro hitting 89.3%.
Regarding deployment and pricing, GPT-5.4 is rolling out across ChatGPT, the API, and Codex. In ChatGPT, "GPT-5.4 Thinking", will replace the previous "GPT-5.2 Thinking", model (please note that GPT-5.2 will officially retire on June 5, 2026, and the older GPT-5.1 series will bid us farewell on March 11, 2026).
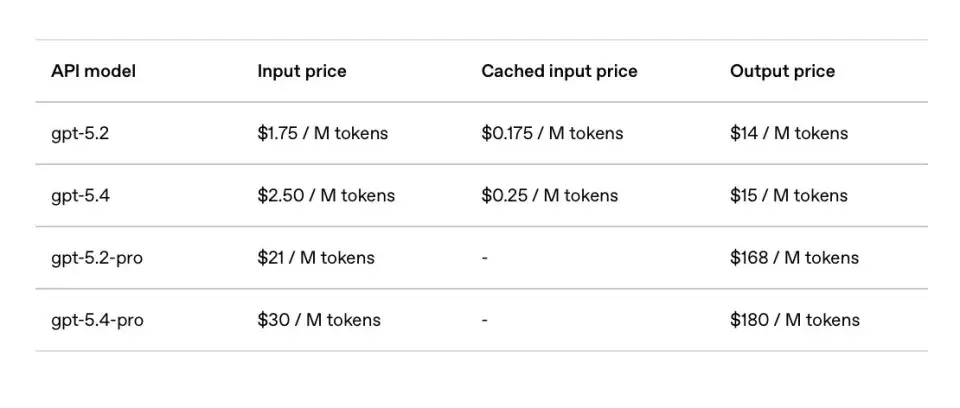
The API pricing reflects its premium capabilities. GPT-5.4 costs $2.50 per million input tokens and $15 per million output tokens. The highly advanced GPT-5.4 Pro (designed for massive code projects and complex automated workflows) is priced at $30 per million input tokens and $180 per million output tokens. While the per-token price is higher than its predecessor, the overall cost for complex tasks might not rise significantly thanks to the highly efficient Tool Search token-saving mechanism.
Final Thoughts on GPT-5.4
The release of GPT-5.4 marks a profound transition in the AI landscape. It represents a move away from models that merely write code toward systems that write code, open browsers to check documentation, invoke APIs to verify results, and compile final reports. With a 75% success rate in computer operations, there is still room for growth (as one in four attempts might still face hiccups), but it is undeniably an incredible milestone.
GPT-5.4 is not just an upgrade. It is a dedicated AI digital employee. The most important question for developers and business leaders is no longer whether AI can do the work, but rather, which tasks are you ready to hand over to GPT-5.4 today?