
Uscita ufficiale di Seedance 2.5: Anteprima tecnica e funzionalità principali
Il 23 giugno 2026, alla FORCE Conference di Volcano Engine, il presidente di Volcano Engine, Tan Dai, ha annunciato ufficialmente il rilascio di Seedance 2.5. Sviluppata dal team Doubao di ByteDance, questa ultima iterazione della linea di generazione video Seedance introduce miglioramenti significativi nella durata dei video, nella capacità di riferimento multimodale e nell'editing semantico. Attualmente in fase di beta testing globale per le aziende, il modello è previsto per il lancio ufficiale all'inizio di luglio 2026.
Progettato per soddisfare le elevate esigenze di coerenza e struttura del cinema, della pubblicità digitale e del design creativo, Seedance 2.5 rappresenta un importante cambiamento strategico verso flussi di lavoro aziendali robusti.

Il percorso evolutivo: da Seedance 1.0 a Seedance 2.5
Lo sviluppo della famiglia di modelli Seedance riflette una timeline rapida incentrata sul superamento dei limiti classici della generazione video AI, in particolare la durata sequenziale e la coerenza temporale.
- Maggio 2025 (Seedance 1.0 Lite): Lanciato come modello fondamentale leggero, questa versione supportava le capacità da testo a video e da immagine a video con una durata massima di 10 secondi.
- Febbraio 2026 (Seedance 2.0): Questo rilascio ha ampliato le capacità di output a video di 30 secondi, sebbene si basasse su tecniche di cucitura sequenziale. Ha introdotto input multimodali iniziali, che hanno attirato l'attenzione globale per la loro precisione. Contemporaneamente all'annuncio della versione 2.5, Volcano Engine ha aggiornato la precedente generazione Seedance 2.0 per supportare la generazione video nativa 4K.
- Giugno 2026 (Seedance 2.5): La versione appena annunciata elimina la necessità di cucitura dei segmenti, supportando la generazione nativa di video a segmento singolo fino a 30 secondi. Espande inoltre significativamente le capacità di riferimento e introduce flussi di lavoro di controllo spaziale profondo.
Esempi video di Seedance 2.5
Principali aggiornamenti tecnici in Seedance 2.5
I miglioramenti funzionali fondamentali di Seedance 2.5 si concentrano sul dare ai creatori un controllo granulare sulla lunghezza temporale, sull'abbinamento stilistico e sull'editing localizzato.
1. Generazione nativa a segmento singolo di 30 secondi
Mentre i precedenti modelli generativi a lungo raggio si basavano tipicamente sulla cucitura di segmenti più brevi (un processo che spesso introduce derive visive o incoerenze strutturali), Seedance 2.5 genera un intero clip di 30 secondi in un unico passaggio nativo. Generare l'intera sequenza in modo continuo garantisce un elevato livello di coerenza temporale e di movimento della telecamera. Questo aggiornamento architetturale supporta il tracciamento fluido della telecamera, panoramiche complesse e flussi narrativi continui, elementi critici per gli storyboard cinematografici e la pubblicità di fascia alta.

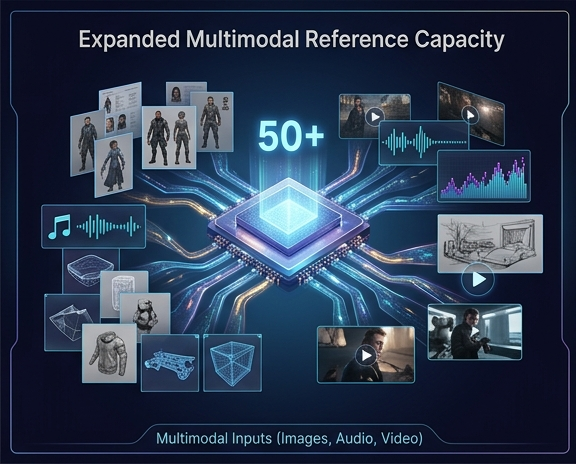
2. Capacità di riferimento multimodale ampliata
Mantenere la coerenza di personaggi e stili tra scene diverse è stata una sfida persistente nella generazione video. Seedance 2.5 affronta questo problema ampliando il numero di input di riferimento simultanei. Il modello ora supporta l'importazione simultanea di fino a 50 asset di riferimento di tutte le modalità (incluse immagini, tracce audio e video di riferimento), che rappresenta un aumento quadruplo rispetto al limite di 12 input in Seedance 2.0. Questa capacità consente ai team di produzione di fornire al modello schede complete dei personaggi, ambientazioni 3D, riferimenti di oggetti di scena e segnali audio contemporaneamente, garantendo un'elevata fedeltà visiva e stilistica nell'output generato.
3. Editing controllabile a grana fine
Per gli editor professionisti, generare un video completamente nuovo per correggere un piccolo errore è altamente inefficiente. Seedance 2.5 risolve questo problema offrendo un editing video semantico preciso. I creatori possono sostituire o modificare elementi specifici all'interno di una scena (come i vestiti di un personaggio, i dettagli ambientali, gli oggetti di scena o l'identità del soggetto) mantenendo completamente intatti il movimento originale dell'attore, gli angoli di ripresa, le condizioni di illuminazione e la composizione complessiva.

4. Pre-visualizzazione 3D pionieristica nel settore (Rendering di layout 3D)
In un'importante innovazione del flusso di lavoro, Seedance 2.5 introduce una funzionalità di pre-visualizzazione di modelli 3D in bianco. I creatori possono inserire un blocco 3D a bassa fedeltà (spesso chiamato nel settore "blocking" o "animatic") insieme a riferimenti stilistici. Il modello quindi rende questi blocchi geometrici in sequenze video dettagliate e visivamente stabili. Questo fornisce un ponte efficiente tra il blocking spaziale in fase iniziale e la visualizzazione finale della scena, abbassando significativamente la barriera tecnica di accesso per la pre-produzione di animazione e VFX.

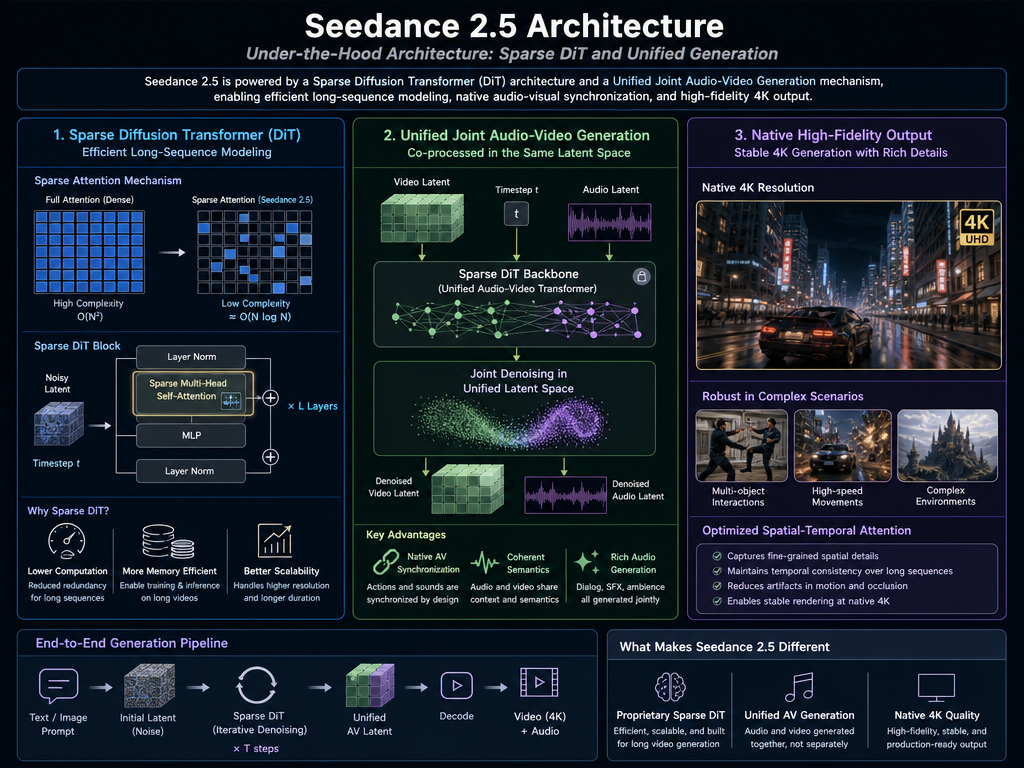
Architettura sotto il cofano: DiT sparso e generazione unificata
Le capacità di Seedance 2.5 sono guidate da importanti cambiamenti strutturali nel modo in cui il modello elabora i dati spaziali e temporali.
- Architettura Sparse Diffusion Transformer (DiT): Basata sul framework proprietario Diffusion Transformer del team Doubao, Seedance 2.5 utilizza un meccanismo di attenzione sparso ottimizzato. Questa architettura riduce la ridondanza computazionale, consentendo al modello di addestrarsi e inferire dati video a sequenza lunga con elevata efficienza.
- Generazione audio-video congiunta unificata: A differenza dei flussi di lavoro tradizionali che generano l'audio separatamente come fase di post-elaborazione, Seedance 2.5 impiega un meccanismo di generazione congiunta unificata. I segnali visivi e uditivi vengono co-elaborati all'interno dello stesso spazio latente, ottenendo una sincronizzazione nativa tra le azioni sullo schermo (come dialoghi, passi o impatti ambientali) e i corrispondenti effetti sonori.
- Output nativo ad alta fedeltà: I meccanismi di attenzione spazio-temporale ottimizzati consentono un rendering stabile a risoluzioni 4K native, mantenendo i dettagli strutturali anche durante interazioni complesse tra più oggetti o movimenti rapidi della telecamera.
Integrazione nell'ecosistema e strategia di commercializzazione
ByteDance ha progettato Seedance 2.5 per integrarsi perfettamente con il suo ecosistema digitale più ampio, inclusi "CapCut", "Dreamina AI", "Doubao" e la piattaforma "Volcano Engine Model Ark".
Da un punto di vista commerciale, il modello riflette un deliberato spostamento verso una monetizzazione aziendale (B-end) sostenibile. Secondo i dati divulgati durante la conferenza, la piattaforma Seedance orientata alle aziende ha stabilito un percorso commerciale praticabile, raggiungendo un fatturato annuo ricorrente (ARR) di 2 miliardi di dollari. Questo flusso di entrate gioca un ruolo critico nel compensare i costi computazionali sostanziali associati all'inferenza su larga scala dei modelli in tutto l'ecosistema Doubao.
Inoltre, ByteDance ha presentato in anteprima la sua nuova piattaforma di commercializzazione del copyright AI durante la conferenza. Con creatori di spicco come Stephen Chow che si sono uniti come partner iniziali, la piattaforma consente ai creatori di realizzare opere derivate legalmente utilizzando modelli di proprietà intellettuale autorizzati, stabilendo un percorso strutturato e conforme per l'utilizzo dell'IP nei media generativi.