
Seedance 2.5 Offizielle Veröffentlichung: Technische Vorschau und Kernfunktionen
Am 23. Juni 2026 gab auf der Volcano Engine FORCE-Konferenz der Präsident von Volcano Engine, Dai Tan, offiziell die Veröffentlichung von Seedance 2.5 bekannt. Diese neueste Iteration der Seedance-Videogenerierungs-Reihe, entwickelt vom Doubao-Team unter ByteDance, führt bedeutende Verbesserungen bei der Videodauer, der multimodalen Referenzkapazität und der semantischen Bearbeitung ein. Derzeit befindet sich das Modell in der globalen Unternehmens-Beta-Phase und soll Anfang Juli 2026 offiziell starten.
Seedance 2.5 wurde entwickelt, um die hohen Anforderungen an Konsistenz und Struktur in den Bereichen Filmproduktion, digitale Werbung und kreatives Design zu erfüllen, und stellt eine wichtige strategische Hinwendung zu robusten Arbeitsabläufen für Unternehmen dar.

Die Entwicklung: Von Seedance 1.0 zu Seedance 2.5
Die Entwicklung der Seedance-Modellfamilie spiegelt einen schnellen Zeitplan wider, der sich auf die Überwindung der klassischen Grenzen der KI-Videogenerierung konzentriert, insbesondere der sequenziellen Dauer und der zeitlichen Kohärenz.
- Mai 2025 (Seedance 1.0 Lite): Als leichtes Basismodell eingeführt, unterstützte diese Version Text-zu-Video- und Bild-zu-Video-Funktionen mit einer maximalen Dauer von 10 Sekunden.
- Februar 2026 (Seedance 2.0): Diese Version erweiterte die Ausgabefähigkeiten auf 30-Sekunden-Videos, basierte jedoch auf sequenziellen Nahttechniken. Sie führte erste multimodale Eingaben ein, die weltweit Aufmerksamkeit für ihre Präzision erregten. Gleichzeitig mit der Ankündigung von Version 2.5 aktualisierte Volcano Engine die vorherige Generation Seedance 2.0, um native 4K-Videogenerierung zu unterstützen.
- Juni 2026 (Seedance 2.5): Die neu angekündigte Version beseitigt die Notwendigkeit von Segmentzusammensetzungen und unterstützt die native Generierung einzelner Videosegmente von bis zu 30 Sekunden. Sie erweitert zudem die Referenzkapazitäten erheblich und führt tiefgehende räumliche Kontrollabläufe ein.
Seedance 2.5 Video-Beispiele
Wichtige technische Verbesserungen in Seedance 2.5
Die zentralen Funktionserweiterungen von Seedance 2.5 konzentrieren sich darauf, den Erstellern eine granulare Kontrolle über die zeitliche Länge, die Stilangleichung und die lokale Bearbeitung zu geben.
1. Native 30-Sekunden-Einzel-Segment-Generierung
Während frühere generative Modelle für lange Formate typischerweise auf das Zusammensetzen kürzerer Segmente angewiesen waren (ein Prozess, der oft visuelle Drift oder strukturelle Inkonsistenzen einführt), gibt Seedance 2.5 einen vollständigen 30-Sekunden-Clip in einem einzigen nativen Durchlauf aus. Die kontinuierliche Generierung der gesamten Sequenz gewährleistet ein hohes Maß an zeitlicher und kamerabewegungsbezogener Kohärenz. Diese architektonische Verbesserung unterstützt flüssige Kamerabewegungen, komplexe Schwenks und kontinuierliche narrative Abläufe, die für cineastische Storyboards und hochwertige Werbung entscheidend sind.

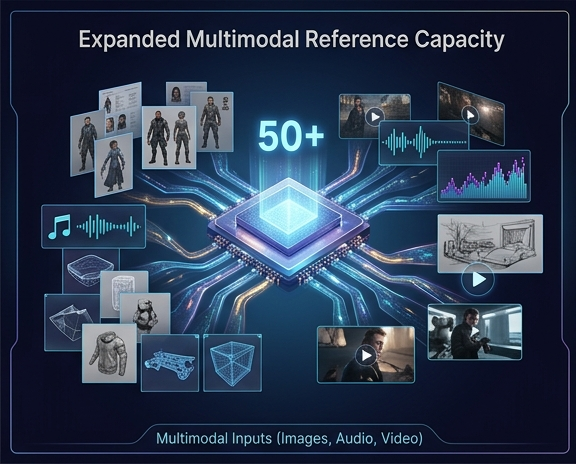
2. Erweiterte multimodale Referenzkapazität
Die Aufrechterhaltung der Charakter- und Stilkonsistenz über verschiedene Szenen hinweg war eine anhaltende Herausforderung bei der generativen Videogenerierung. Seedance 2.5 begegnet diesem Problem, indem die Anzahl der gleichzeitigen Referenzeingaben erhöht wird. Das Modell unterstützt nun den gleichzeitigen Import von bis zu 50 Referenz-Assets aller Modalitäten (einschließlich Bilder, Audiospuren und Referenzvideos), was einer Vervierfachung gegenüber dem 12-Eingabe-Limit in Seedance 2.0 entspricht. Diese Kapazität ermöglicht es Produktionsteams, dem Modell gleichzeitig umfassende Charakterblätter, Umgebungsansichten, Requisitenreferenzen und Audio-Cues zuzuführen, was eine hohe visuelle und stilistische Genauigkeit über die generierte Ausgabe hinweg gewährleistet.
3. Kontrollierbare feinkörnige Bearbeitung
Für professionelle Editoren ist es äußerst ineffizient, ein völlig neues Video zu generieren, um einen kleinen Fehler zu beheben. Seedance 2.5 begegnet diesem Problem durch präzise semantische Videobearbeitung. Ersteller können bestimmte Elemente innerhalb einer Szene ersetzen oder ändern (z. B. die Kleidung einer Figur, Umgebungsdetails, Requisiten oder die Identität des Subjekts), während die ursprüngliche Schauspielerbewegung, die Kameraperspektive, die Lichtverhältnisse und die gesamte Komposition vollständig intakt bleiben.

4. Branchenweit erste 3D-Visualisierung (3D-Layout-Rendering)
In einer bedeutenden Innovation der Arbeitsabläufe führt Seedance 2.5 eine Funktion zur Vorvisualisierung mit 3D-Weißmodellen ein. Ersteller können ein Low-Fidelity-3D-Blockout (in der Branche oft als "Blocking" oder "Animatic" bezeichnet) zusammen mit Stilreferenzen eingeben. Das Modell rendert diese geometrischen Blöcke dann in detaillierte, visuell stabile Videosequenzen. Dies bietet eine effiziente Brücke zwischen der räumlichen Blockierung in der frühen Phase und der endgültigen Szenenvisualisierung, wodurch die technische Einstiegshürde für die Animation und VFX-Vorproduktion deutlich gesenkt wird.

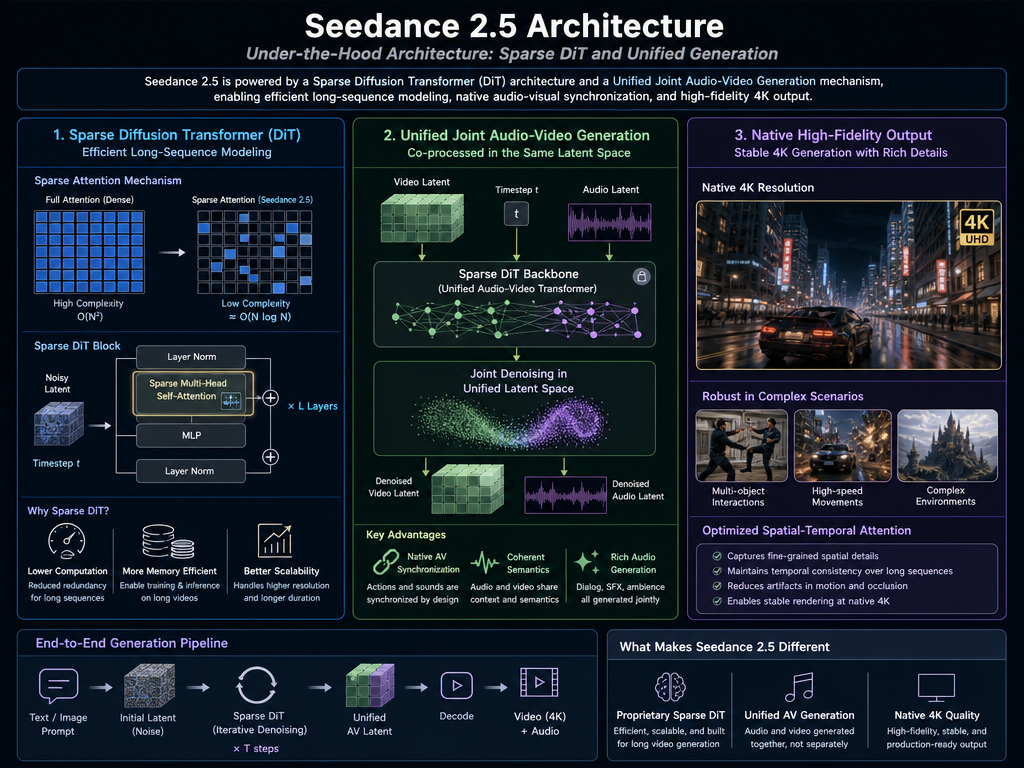
Architektur im Inneren: Sparse DiT und einheitliche Generierung
Die Fähigkeiten von Seedance 2.5 werden durch wesentliche strukturelle Änderungen in der Art und Weise, wie das Modell räumliche und zeitliche Daten verarbeitet, ermöglicht.
- Sparse-Diffusion-Transformer (DiT)-Architektur: Aufbauend auf dem proprietären Diffusion-Transformer-Framework des Doubao-Teams verwendet Seedance 2.5 einen optimierten Sparse-Attention-Mechanismus. Diese Architektur reduziert rechnerische Redundanz, sodass das Modell mit hoher Effizienz auf langsequenziellen Videodaten trainieren und inferieren kann.
- Einheitliche gemeinsame Audio-Video-Generierung: Im Gegensatz zu traditionellen Arbeitsabläufen, bei denen Audio als separater Nachbearbeitungsschritt generiert wird, verwendet Seedance 2.5 einen einheitlichen gemeinsamen Generierungsmechanismus. Visuelle und auditive Signale werden im selben latenten Raum gemeinsam verarbeitet, was zu einer natives Synchronisation zwischen den Bildschirmaktionen (wie Dialog, Schritte oder Umwelteinflüsse) und ihren entsprechenden Soundeffekten führt.
- Native High-Fidelity-Ausgabe: Die optimierten räumlich-zeitlichen Aufmerksamkeitsmechanismen ermöglichen ein stabiles Rendern in nativen 4K-Auflösungen, wobei strukturelle Details auch bei komplexen Multi-Objekt-Interaktionen oder schnellen Kamerabewegungen erhalten bleiben.
Ökosystem-Integration und Kommerzialisierungsstrategie
ByteDance hat Seedance 2.5 so konzipiert, dass es sich nahtlos in sein breiteres digitales Ökosystem integriert, einschließlich "CapCut", "Dreamina KI", "Doubao" und der "Volcano Engine Model Ark"-Plattform.
Aus geschäftlicher Perspektive spiegelt das Modell eine bewusste Hinwendung zu einer nachhaltigen Monetarisierung auf Unternehmensebene (B-End) wider. Laut auf der Konferenz veröffentlichten Daten hat die unternehmensorientierte Seedance-Plattform einen tragfähigen kommerziellen Pfad etabliert und einen jährlich wiederkehrenden Umsatz (ARR) von 2 Milliarden Dollar erreicht. Dieser Umsatzstrom spielt eine entscheidende Rolle bei der Kompensation der erheblichen Rechenkosten, die mit der großflächigen Modellinferenz im Doubao-Ökosystem verbunden sind.
Darüber hinaus stellte ByteDance auf der Konferenz seine neue KI-Copyright-Kommerzialisierungsplattform vor. Mit prominenten Kreativen wie Stephen Chow als ersten Partnern ermöglicht die Plattform es den Erstellern, rechtlich abgeleitete Werke unter Verwendung lizenzierter geistiger Eigentumsvorlagen zu erstellen, und schafft so einen strukturierten, konformen Weg für die Nutzung von geistigem Eigentum in der generativen Medienproduktion.